1 Introduction
(Architecture-based CL approaches and its network capacity problem)
(How architecture-based apporaches like HAT and AdaHAT alleviate network capacity problem)
(The paradox of addressing network capacity problem in a fix-sized network)
(Machine unlearning helps recycling model capacity in architecture-based CL, beyond its original purpose for elimination of requested user data)
(Why choosing fixed-sized architecture-based CL approaches)
(Contribution: 1. CL + MU, 2. MU addressing model capacity problem)
3 Methodology
In this section, we try to propose a new architecture-based CL approach, AmnesiacHAT, which extends Hard Attention to the Task (HAT) (Serra et al. 2018) equipped with the ability of unlearning a specified task.
3.1 Problem Definition
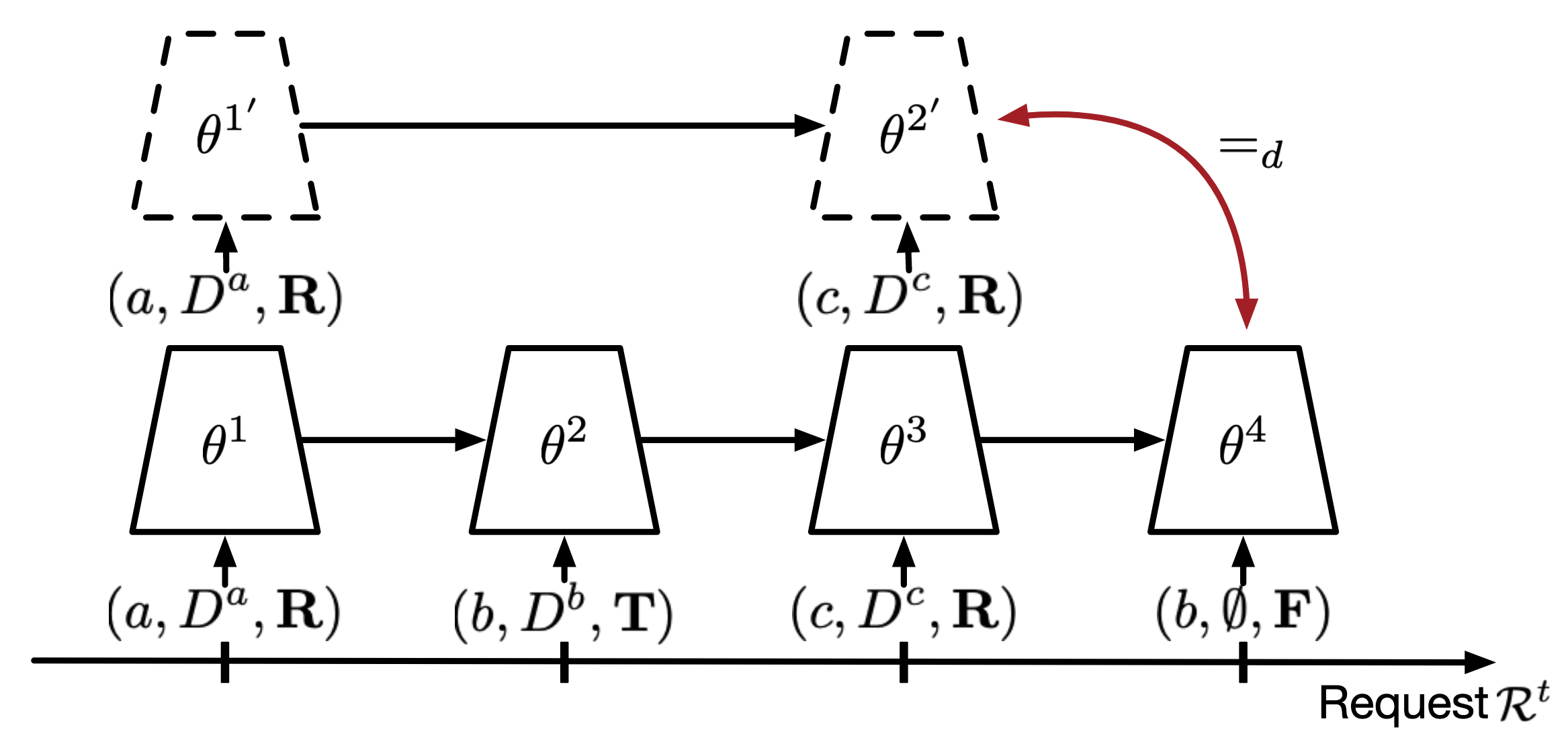
We limit our scope in TIL (Task-Incremental Learning) (Wang et al. 2024) and adopt the paradigm that CLPU (Liu, Liu, and Stone 2022) proposed:
- Task sequence: \(t = 1, 2, \cdots, N\)
- Dataset for task \(t\): \(D^t = \{x^t, y^t\}\), training, validation, and test set.
- Permanent mark: \(P(t)\), which is a binary value indicating whether task \(t\) is permanent or not. If permanent, it cannot be unlearned in the future.
- Unlearning request: at the end of training task \(t\), the user requests to unlearn tasks \(u(t)\). It can be multiple. If empty, no unlearning request. Note that the unlearning request is not allowed to contain permanent tasks.
- Unlearned tasks: \(U(t)\) the unlearned task list so far after unlearning request of task \(t\). \(U(t) = \cup_{\tau=1}^t u(\tau)\).
- Remaining tasks: \(R(t)\) the remaining (not unlearned) task list after unlearning request of task \(t\).
- Protocol:
- Training task \(t\): the model \(f\) is trained on \(D^t\) (from \(f^{(t-1)}\) to \(f^{(t)}\)).
- Deciding if permanent: the user has the right to decide whether task \(t\) is permanent or not. Once becoming permanent, it cannot be reversed.
- Unlearning task \(t\): the model is unlearned on \(u(t)\).
- Testing: the model is tested on \(R(t)\).
- CL goal: achieve good performance on all tasks \(1, \cdots, t\) after training task \(t\)
- Unlearning goal: two models being similar: 1. this model (having learned all tasks but unlearned \(U(t)\)) 2. a reference model (only learned \(R(t)\))
Note that my method doesn’t need to distinguish the permanent tasks (which are surely unable to unlearn) and temporary tasks (which are ready to unlearn in the future) like CLPU did, which breaks the limitation of CLPU (could be considered as my contribution). However, if we know the information of a task being permanent or temporary, we can use it to improve the unlearning mechanism, which I will discuss in Section 3.5.
(Kedian’s suggestion) If this unlearning scenario is too difficult, set a deadline for the unlearning request, i.e. the user can only request to unlearn tasks after certain tasks away (e.g. \(t-t_d\)). That is, the non-permanent tasks automatically become permanent after \(t_d\) tasks.
the unlearning request can be made at any time, not only at the end of training task \(t\). This is because the user can request to unlearn a task at any time, and the model should be able to handle it.
构造的其他的sequence场景,可以放在后面的章节或者补充实验,可以讨论出更多的结果。
3.2 AdaHAT: The CL Algorithm
We use AdaHAT, which is a fixed-sized architecture-based CL approach extended from HAT. In HAT, layer-wise attention vectors (masks) \(\mathbf{m}_l^t\) with binary values are learned to pay hard attention on units in each layer. Each mask select a subnetwork for the task for training, test and prediction.
Note that HAT-based architecture allow mask overlapping. The ways HAT and AdaHAT deal with the overlapping when training are different. Let’s say we are training task \(t\) with a subnet selected that also overlaps with previous tasks. HAT simply fixed those overlapping parameters and not update them anymore, which prioritises previous task, while AdaHAT allows an adaptive adjustment on the overlapping parameters, which is a way to release some capacity of the network. That’s also the underlying mechanism where HAT stresses too much on stability and AdaHAT tries to balance the stability and plasticity.
3.3 Unlearning Task in AdaHAT
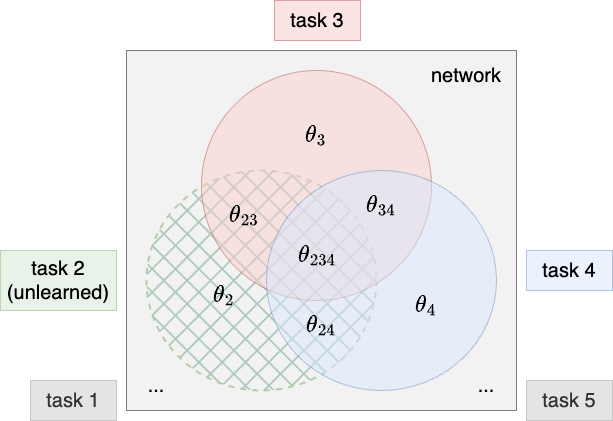
The separability of tasks in architecture-based approaches makes it so much easier to unlearn a task. However, AdaHAT is not completely separable in terms of tasks because of the overlapping of subnetworks. We only need to find a way to deal with the overlapping parts when unlearning a task. For the non-overlapping parts, reinializing them is enough to wipe out the knowledge of the task without affecting other tasks.
A parameter is changed by a stack of additive task-wise update:
\[\theta_{l,ij}^{(t)} = \theta_{l,ij}^{(0)} + \Delta\theta_{l,ij}^{(1)} + \cdots + \Delta\theta_{l,ij}^{(t)}\]
where \(\theta_{l,ij}^{(0)}\) is the intialisation, and \(\Delta\theta_{l,ij}^{(\tau)}, \tau=1,\cdots,t\) is the update for task \(\tau\).
In HAT, only the first task \(\tau\) that occupies the parameter can update it, and the rest of tasks that overlap with it can’t update it anymore. That is to say, only one \(\Delta\theta_{l,ij}^{(\tau)}\) is non-zero.
In AdaHAT, all the following tasks that overlap with \(\theta_{l,ij}\) can update it, but the update is “adjustment” in a very small scale (determined by the hyperparameter overall intensity \(\alpha\)). That is to say, \(\Delta\theta_{l,ij}^{(\tau)}\) are zero after a series of \(\tau\)s, then comes a huge update at the first occupying task, and then a series of small updates (could be zero) at the following tasks.
When unlearning a task \(\tau\), we need to reserve the update of parameters during training the task. Inspired by above, we can simply remove the \(\Delta{\theta}^{(\tau)}\) from the trace by subtracting it. This requires us to store the above task-wise update trajectory of the parameters \(\Delta{\theta}^{(\tau)}, \tau=1, \cdots, t\). (The initialisation \(\theta^{(0)}\) is not needed to be stored because it is fixed and can be reinitialised with the seed when unlearning).
An important thing to note is that the unbalanced updates between the first occupying task and the following tasks make unlearning the first occupying task different from others. If we subtract the first occupying task’s update, i.e. the huge one, the following tasks’ updates will be too ineffective to change the parameters from initialisation. To address this problem, I simply compensate the next task’s update by zooming it up to the same scale as the first occupying task’s update: specifically, multiply it by the overall intensity \(\alpha\).
3.4 How Does It Recycle Model Capacity?
Reintialising the non-overlapping part of the parameters make room for future tasks to occupy, which automatically recycles model capacity.
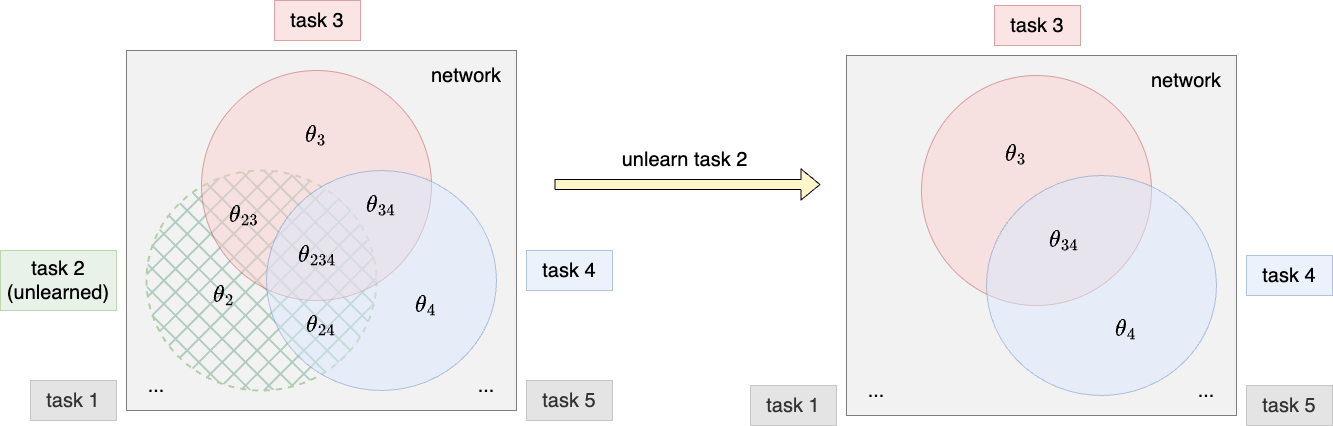
For subtracting task-wise update of overlapping parts, we can think it in this way: If parameters are the results of addition of too many task-wise updates, its significance on each task is naturally diluted. Reversing the dilution by subtracting its component is an implicit way to release the capacity.
3.5 Optimize Update Trajectory Storage
which could be a huge memory cost. We can optimize the storage in two ways:
- Sparse storage: only store the non-zero updates.
- Prune the less effective update. We can set a threshold to remove the update that is too small to affect the parameters. Alternatively, since the update can be broken down into steps, prune those which have too many steps without update (This could definitely happen in AdaHAT, as the masks are learned and changing in steps. Imagine a parameter is masked in certain step and sooner unmasked in the next step).
- Concat the update for the permanent tasks. If we know a task is permanent, we can concatenate the update of the task with the previous task. This is because the update of the permanent task is not needed to be stored separately.
Sparse matrix storage? Matrix compression?
4 Experiment
4.1 Setup
Datasets. We could use simple datasets like CLPU did, such as SplitMNIST. The focus of the work is on unlearning so it’s more important to construct different scenarios of unlearning requests.
Baselines. CLPU compares with some CL approaches like LwF, EWC, but they are without unlearning mechanism and nothing to do with unlearning at all. I found their unlearning is to do nothing, which is not fair enough. I think we could probably apply some naive unlearning mechanism to those CL apparoaches, such as reinitialize the weights of the task to be unlearned. But simply following what CLPU was using is probably fine.
4.2 Metrics
For continual unlearning paradigm, we need to prove both the effectiveness of continual learning and unlearning. The metrics that CLPU uses comprises of the following:
- CL metric on the testset of all remaining tasks. This includes the performance matrix (accuracy, loss, etc.) and the overall metrics. Please refer to my article for CL metrics.
CL Metric 这个地方可以算difference吗?
Unlearning metric: distribution distances between outputs of the model and a reference model, on the testset of each unlearned task:
- The current model \(f^{(t)}\), which learns the entire task sequence but unlearned the requested tasks.
- The reference model \(f_{\text{ref}}^{(t)}\), which only learns the remaining tasks.
The smaller the distance, the better the unlearning, as if the model has never meet the unlearned tasks.
牟老师想法:reference retrain model 在每个之前的任务上都跑,算一个更综合的指标。
An Improvement to the Unlearning Metric
There is a problem when I implement the unlearning metric. It is unclear about what “outputs” of a model means. I learned that CLPU uses the output logits from its codes. This causes problems in TIL setting. In TIL, we use a multi-head classifier architecture where tasks share a backbone (a.k.a. feature extractor) and have their own independent output head (please refer to my article). The output logits can be solely controlled by the output head rather than the backbone, causing two problems:
- The unlearning algorithm can simply cheat by reinitialising the output head of the unlearned task.
- Since the reference model has nothing to do with unlearned tasks, which means by default there are no output heads for the unlearned tasks, the output logits of the unlearned tasks are not available. If we simply create output heads for the unlearned tasks with a random initialisation, the metric also loses its meaning.
(In CLPU codes, I suprisedly found they don’t distinguish output heads as all tasks has the same number of classes. This is not the common practice in TIL setting.)
Therefore, I propose another way to measure unlearning effectiveness: distribution distances between the feature extracted by the backbone instead of output logits, solving the above problems. Here is the formal definition:
Let \(B\) be the backbone network, \(B^{(t)}\) be the backbone of the model \(f^{(t)}\), and \(B_{\text{ref}}^{(t)}\) be the backbone of the reference model \(f_{\text{ref}}^{(t)}\). The unlearning metric (temporarily called Jensen-Shannon Distance(JSD)) is defined as:
\[\text{JSD}_t = \frac{1}{|U(t)|} \sum_{\tau \in U(t)} \frac{1}{|D^\tau_{\text{test}}|} \sum_{(x, y) \in D^\tau_{\text{test}}}\text{JS}\left(B^{(t)}(x) \| B_{\text{ref}}^{(t)}(x)\right)\]
where \(\text{JS}(\cdot, \cdot)\) is the Jensen-Shannon divergence, \(D^\tau_{\text{test}}\) is the testset of unlearned task \(\tau\).
修改: 1. cosine相似度?欧氏距离? 2. KL不能用在非分布上。可以加softmax
Additional Metric to Measure the Benefit of Model Capacity Release
We propose a novel metric to measure the benefit of model capacity release, which compares the performance on remaining tasks with and without unlearning the requested tasks. Therefore we have another reference model which doesn’t unlearn the requested tasks:
- The full model \(f_{\text{full}}^{(t)}\), which learns the entire task sequence without unlearning the requested tasks.
If the former is better, it proves that the model capacity is released and taking effect on the continual learning performance.
Let \(B_{\text{full}}^{(t)}\) be the backbone of the full model \(f_{\text{full}}^{(t)}\), \(a_{\tau,t}\) be the accuracy on task \(\tau\) after learning task \(t\), \(a^{\text{full}}_{\tau,t}\) be the corresponding full model’s accuracy. The metric we propose called Accuracy Difference (AD) is defined as:
\[\text{AD}_t = \frac{1}{|R(t)|} \sum_{\tau \in R(t)} \left(a_{\tau,t} - a^{\text{full}}_{\tau,t}\right)\]
4.3 Results
TBC.
5 Questions
Potential names: AmnesiacHAT or Amnesiac CL?
References
r”“” The submodule in backbones for the MLP backbone network. It includes multiple versions of MLP, including the basic MLP, the continual learning MLP, the HAT masked MLP, and the WSN masked MLP. ““”
all = [“MLP”, “CLMLP”, “HATMaskMLP”, “AmnesiacHATMLP”, “WSNMaskMLP”]
import logging from copy import deepcopy
from torch import Tensor, nn
from clarena.backbones import ( AmnesiacHATBackbone, Backbone, CLBackbone, HATMaskBackbone, WSNMaskBackbone, )
6 always get logger for built-in logging in each module
pylogger = logging.getLogger(name)
class MLP(Backbone): “““Multi-layer perceptron (MLP), a.k.a. fully connected network.
MLP is a dense network architecture with several fully connected layers, each followed by an activation function. The last layer connects to the output heads.
"""
def __init__(
self,
input_dim: int,
hidden_dims: list[int],
output_dim: int,
activation_layer: nn.Module | None = nn.ReLU,
batch_normalization: bool = False,
bias: bool = True,
dropout: float | None = None,
**kwargs,
) -> None:
r"""Construct and initialize the MLP backbone network.
**Args:**
- **input_dim** (`int`): The input dimension. Any data need to be flattened before entering the MLP. Note that it is not required in convolutional networks.
- **hidden_dims** (`list[int]`): List of hidden layer dimensions. It can be an empty list, which means a single-layer MLP, and it can be as many layers as you want. Note that it doesn't include the last dimension, which we take as the output dimension.
- **output_dim** (`int`): The output dimension that connects to output heads.
- **activation_layer** (`nn.Module` | `None`): Activation function of each layer (if not `None`). If `None`, this layer won't be used. Default `nn.ReLU`.
- **batch_normalization** (`bool`): Whether to use batch normalization after the fully connected layers. Default `False`.
- **bias** (`bool`): Whether to use bias in the linear layer. Default `True`.
- **dropout** (`float` | `None`): The probability for the dropout layer. If `None`, this layer won't be used. Default `None`.
- **kwargs**: Reserved for multiple inheritance.
"""
super().__init__(output_dim=output_dim, **kwargs)
self.input_dim: int = input_dim
r"""The input dimension of the MLP backbone network."""
self.hidden_dims: list[int] = hidden_dims
r"""The hidden dimensions of the MLP backbone network."""
self.output_dim: int = output_dim
r"""The output dimension of the MLP backbone network."""
self.num_fc_layers: int = len(hidden_dims) + 1
r"""The number of fully-connected layers in the MLP backbone network, which helps form the loops in constructing layers and forward pass."""
self.batch_normalization: bool = batch_normalization
r"""Whether to use batch normalization after the fully-connected layers."""
self.activation: bool = activation_layer is not None
r"""Whether to use activation function after the fully-connected layers."""
self.dropout: bool = dropout is not None
r"""Whether to use dropout after the fully-connected layers."""
self.fc: nn.ModuleList = nn.ModuleList()
r"""The list of fully connected (`nn.Linear`) layers."""
if self.batch_normalization:
self.fc_bn: nn.ModuleList = nn.ModuleList()
r"""The list of batch normalization (`nn.BatchNorm1d`) layers after the fully connected layers."""
if self.activation:
self.fc_activation: nn.ModuleList = nn.ModuleList()
r"""The list of activation layers after the fully connected layers."""
if self.dropout:
self.fc_dropout: nn.ModuleList = nn.ModuleList()
r"""The list of dropout layers after the fully connected layers."""
# construct the weighted fully connected layers and attached layers (batch norm, activation, dropout, etc.) in a loop
for layer_idx in range(self.num_fc_layers):
# the input and output dim of the current weighted layer
layer_input_dim = (
self.input_dim if layer_idx == 0 else self.hidden_dims[layer_idx - 1]
)
layer_output_dim = (
self.hidden_dims[layer_idx]
if layer_idx != len(self.hidden_dims)
else self.output_dim
)
# construct the fully connected layer
self.fc.append(
nn.Linear(
in_features=layer_input_dim,
out_features=layer_output_dim,
bias=bias,
)
)
# update the weighted layer names
full_layer_name = f"fc/{layer_idx}"
self.weighted_layer_names.append(full_layer_name)
# construct the batch normalization layer
if self.batch_normalization:
self.fc_bn.append(nn.BatchNorm1d(num_features=(layer_output_dim)))
# construct the activation layer
if self.activation:
self.fc_activation.append(activation_layer())
# construct the dropout layer
if self.dropout:
self.fc_dropout.append(nn.Dropout(dropout))
def forward(
self, input: Tensor, stage: str = None
) -> tuple[Tensor, dict[str, Tensor]]:
r"""The forward pass for data. It is the same for all tasks.
**Args:**
- **input** (`Tensor`): The input tensor from data.
**Returns:**
- **output_feature** (`Tensor`): The output feature tensor to be passed into heads. This is the main target of backpropagation.
- **activations** (`dict[str, Tensor]`): The hidden features (after activation) in each weighted layer. Keys (`str`) are the weighted layer names and values (`Tensor`) are the hidden feature tensors. This is used for certain algorithms that need to use hidden features for various purposes.
"""
batch_size = input.size(0)
activations = {}
x = input.view(batch_size, -1) # flatten before going through MLP
for layer_idx, layer_name in enumerate(self.weighted_layer_names):
x = self.fc[layer_idx](x) # fully-connected layer first
if self.batch_normalization:
x = self.fc_bn[layer_idx](
x
) # batch normalization can be before or after activation. We put it before activation here
if self.activation:
x = self.fc_activation[layer_idx](x) # activation function third
activations[layer_name] = x # store the hidden feature
if self.dropout:
x = self.fc_dropout[layer_idx](x) # dropout last
output_feature = x
return output_feature, activationsclass CLMLP(CLBackbone, MLP): “““Multi-layer perceptron (MLP), a.k.a. fully connected network. Used as a continual learning backbone.
MLP is a dense network architecture with several fully connected layers, each followed by an activation function. The last layer connects to the CL output heads.
"""
def __init__(
self,
input_dim: int,
hidden_dims: list[int],
output_dim: int,
activation_layer: nn.Module | None = nn.ReLU,
batch_normalization: bool = False,
bias: bool = True,
dropout: float | None = None,
**kwargs,
) -> None:
r"""Construct and initialize the CLMLP backbone network.
**Args:**
- **input_dim** (`int`): the input dimension. Any data need to be flattened before going in MLP. Note that it is not required in convolutional networks.
- **hidden_dims** (`list[int]`): list of hidden layer dimensions. It can be empty list which means single-layer MLP, and it can be as many layers as you want. Note that it doesn't include the last dimension which we take as output dimension.
- **output_dim** (`int`): the output dimension which connects to CL output heads.
- **activation_layer** (`nn.Module` | `None`): activation function of each layer (if not `None`), if `None` this layer won't be used. Default `nn.ReLU`.
- **batch_normalization** (`bool`): whether to use batch normalization after the fully-connected layers. Default `False`.
- **bias** (`bool`): whether to use bias in the linear layer. Default `True`.
- **dropout** (`float` | `None`): the probability for the dropout layer, if `None` this layer won't be used. Default `None`.
- **kwargs**: Reserved for multiple inheritance.
"""
super().__init__(
input_dim=input_dim,
hidden_dims=hidden_dims,
output_dim=output_dim,
activation_layer=activation_layer,
batch_normalization=batch_normalization,
bias=bias,
dropout=dropout,
**kwargs,
)
def forward(
self, input: Tensor, stage: str = None, task_id: int | None = None
) -> tuple[Tensor, dict[str, Tensor]]:
r"""The forward pass for data. It is the same for all tasks.
**Args:**
- **input** (`Tensor`): The input tensor from data.
**Returns:**
- **output_feature** (`Tensor`): The output feature tensor to be passed into heads. This is the main target of backpropagation.
- **activations** (`dict[str, Tensor]`): The hidden features (after activation) in each weighted layer. Key (`str`) is the weighted layer name; value (`Tensor`) is the hidden feature tensor. This is used for continual learning algorithms that need hidden features for various purposes.
- **task_id** (`int` | `None`): The task ID of the current data. Although it is not used in this basic CLMLP, it is provided for API consistency for other continual learning backbones that inherit this `forward()` method.
"""
return MLP.forward(self, input, stage) # call the MLP forward methodclass HATMaskMLP(HATMaskBackbone, MLP): r”““HAT-masked multi-layer perceptron (MLP).
[HAT (Hard Attention to the Task, 2018)](http://proceedings.mlr.press/v80/serra18a) is an architecture-based continual learning approach that uses learnable hard attention masks to select task-specific parameters.
MLP is a dense network architecture with several fully connected layers, each followed by an activation function. The last layer connects to the CL output heads.
The mask is applied to units (neurons) in each fully connected layer. The mask is generated from the neuron-wise task embedding and the gate function.
"""
def __init__(
self,
input_dim: int,
hidden_dims: list[int],
output_dim: int,
gate: str,
activation_layer: nn.Module | None = nn.ReLU,
batch_normalization: str | None = None,
bias: bool = True,
dropout: float | None = None,
**kwargs,
) -> None:
r"""Construct and initialize the HAT-masked MLP backbone network with task embeddings.
**Args:**
- **input_dim** (`int`): The input dimension. Any data need to be flattened before entering the MLP.
- **hidden_dims** (`list[int]`): List of hidden layer dimensions. It can be an empty list, which means a single-layer MLP, and it can be as many layers as you want. Note that it doesn't include the last dimension, which we take as the output dimension.
- **output_dim** (`int`): The output dimension that connects to CL output heads.
- **gate** (`str`): The type of gate function turning real-valued task embeddings into attention masks; one of:
- `sigmoid`: the sigmoid function.
- **activation_layer** (`nn.Module` | `None`): Activation function of each layer (if not `None`). If `None`, this layer won't be used. Default `nn.ReLU`.
- **batch_normalization** (`str` | `None`): How to use batch normalization after the fully connected layers; one of:
- `None`: no batch normalization layers.
- `shared`: use a single batch normalization layer for all tasks. Note that this can cause catastrophic forgetting.
- `independent`: use independent batch normalization layers for each task.
- **bias** (`bool`): Whether to use bias in the linear layer. Default `True`.
- **dropout** (`float` | `None`): The probability for the dropout layer. If `None`, this layer won't be used. Default `None`.
- **kwargs**: Reserved for multiple inheritance.
"""
super().__init__(
output_dim=output_dim,
gate=gate,
input_dim=input_dim,
hidden_dims=hidden_dims,
activation_layer=activation_layer,
batch_normalization=(
True
if batch_normalization == "shared"
or batch_normalization == "independent"
else False
),
bias=bias,
dropout=dropout,
**kwargs,
)
# construct the task embedding for each weighted layer
for layer_idx in range(self.num_fc_layers):
full_layer_name = f"fc/{layer_idx}"
layer_output_dim = (
hidden_dims[layer_idx] if layer_idx != len(hidden_dims) else output_dim
)
self.task_embedding_t[full_layer_name] = nn.Embedding(
num_embeddings=1, embedding_dim=layer_output_dim
)
self.batch_normalization: str | None = batch_normalization
r"""The way to use batch normalization after the fully-connected layers. This overrides the `batch_normalization` argument in `MLP` class. """
# construct the batch normalization layers if needed
if self.batch_normalization == "independent":
self.fc_bns: nn.ModuleDict = nn.ModuleDict() # initially empty
r"""Independent batch normalization layers are stored in a `ModuleDict`. Keys are task IDs and values are the corresponding batch normalization layers for the `nn.Linear`. We use `ModuleDict` rather than `dict` to ensure `LightningModule` can track these model parameters for purposes such as automatic device transfer and model summaries.
Note that the task IDs must be string type in order to let `LightningModule` identify this part of the model."""
self.original_fc_bn_state_dict: dict = deepcopy(self.fc_bn.state_dict())
r"""The original batch normalization state dict as the source for creating new independent batch normalization layers. """
def setup_task_id(self, task_id: int) -> None:
r"""Set up task `task_id`. This must be done before the `forward()` method is called.
**Args:**
- **task_id** (`int`): The target task ID.
"""
HATMaskBackbone.setup_task_id(self, task_id=task_id)
if self.batch_normalization == "independent":
if self.task_id not in self.fc_bns.keys():
self.fc_bns[f"{self.task_id}"] = deepcopy(self.fc_bn)
def get_bn(self, stage: str, test_task_id: int | None) -> nn.Module | None:
r"""Get the batch normalization layer used in the `forward()` method for different stages.
**Args:**
- **stage** (`str`): The stage of the forward pass; one of:
1. 'train': training stage.
2. 'validation': validation stage.
3. 'test': testing stage.
- **test_task_id** (`int` | `None`): The test task ID. Applies only to the testing stage. For other stages, it is `None`.
**Returns:**
- **fc_bn** (`nn.Module` | `None`): The batch normalization module.
"""
if self.batch_normalization == "independent" and stage == "test":
return self.fc_bns[f"{test_task_id}"]
else:
return self.fc_bn
def initialize_independent_bn(self) -> None:
r"""Initialize the independent batch normalization layer for the current task. This is called when a new task is created. Applies only when `batch_normalization` is 'independent'."""
if self.batch_normalization == "independent":
self.fc_bn.load_state_dict(self.original_fc_bn_state_dict)
def store_bn(self) -> None:
r"""Store the batch normalization layer for the current task `self.task_id`. Applies only when `batch_normalization` is 'independent'."""
if self.batch_normalization == "independent":
self.fc_bns[f"{self.task_id}"] = deepcopy(self.fc_bn)
def forward(
self,
input: Tensor,
stage: str,
s_max: float | None = None,
batch_idx: int | None = None,
num_batches: int | None = None,
test_task_id: int | None = None,
) -> tuple[Tensor, dict[str, Tensor], dict[str, Tensor]]:
r"""The forward pass for data from task `self.task_id`. Task-specific masks for `self.task_id` are applied to units (neurons) in each fully connected layer.
**Args:**
- **input** (`Tensor`): The input tensor from data.
- **stage** (`str`): The stage of the forward pass; one of:
1. 'train': training stage.
2. 'validation': validation stage.
3. 'test': testing stage.
- **s_max** (`float`): The maximum scaling factor in the gate function. Doesn't apply to the testing stage. See Sec. 2.4 in the [HAT paper](http://proceedings.mlr.press/v80/serra18a).
- **batch_idx** (`int` | `None`): The current batch index. Applies only to the training stage. For other stages, it is `None`.
- **num_batches** (`int` | `None`): The total number of batches. Applies only to the training stage. For other stages, it is `None`.
- **test_task_id** (`int` | `None`): The test task ID. Applies only to the testing stage. For other stages, it is `None`.
**Returns:**
- **output_feature** (`Tensor`): The output feature tensor to be passed into heads. This is the main target of backpropagation.
- **mask** (`dict[str, Tensor]`): The mask for the current task. Keys (`str`) are the layer names and values (`Tensor`) are the mask tensors. The mask tensor has size (number of units, ).
- **activations** (`dict[str, Tensor]`): The hidden features (after activation) in each weighted layer. Keys (`str`) are the weighted layer names and values (`Tensor`) are the hidden feature tensors. This is used for continual learning algorithms that need hidden features. Although the HAT algorithm does not need this, it is still provided for API consistency for other HAT-based algorithms that inherit this `forward()` method of the `HAT` class.
"""
batch_size = input.size(0)
activations = {}
mask = self.get_mask(
stage=stage,
s_max=s_max,
batch_idx=batch_idx,
num_batches=num_batches,
test_task_id=test_task_id,
)
if self.batch_normalization:
fc_bn = self.get_bn(stage=stage, test_task_id=test_task_id)
x = input.view(batch_size, -1) # flatten before going through MLP
for layer_idx, layer_name in enumerate(self.weighted_layer_names):
x = self.fc[layer_idx](x) # fully-connected layer first
if self.batch_normalization:
x = fc_bn[layer_idx](x) # batch normalization second
x = x * mask[f"fc/{layer_idx}"] # apply the mask to the parameters second
if self.activation:
x = self.fc_activation[layer_idx](x) # activation function third
activations[layer_name] = x # store the hidden feature
if self.dropout:
x = self.fc_dropout[layer_idx](x) # dropout last
output_feature = x
return output_feature, mask, activationsclass AmnesiacHATMLP(AmnesiacHATBackbone, HATMaskMLP):
def __init__(
self,
input_dim: int,
hidden_dims: list[int],
output_dim: int,
gate: str,
activation_layer: nn.Module | None = nn.ReLU,
batch_normalization: str | None = None,
bias: bool = True,
dropout: float | None = None,
**kwargs,
) -> None:
r"""Construct and initialize the AmnesiacHAT MLP backbone network.
**Args:**
- **input_dim** (`int`): The input dimension. Any data need to be flattened before entering the MLP.
- **hidden_dims** (`list[int]`): List of hidden layer dimensions. It can be an empty list, which means a single-layer MLP, and it can be as many layers as you want. Note that it doesn't include the last dimension, which we take as the output dimension.
- **output_dim** (`int`): The output dimension that connects to CL output heads.
- **gate** (`str`): The type of gate function turning real-valued task embeddings into attention masks; one of:
- `sigmoid`: the sigmoid function.
- **activation_layer** (`nn.Module` | `None`): Activation function of each layer (if not `None`). If `None`, this layer won't be used. Default `nn.ReLU`.
- **batch_normalization** (`str` | `None`): How to use batch normalization after the fully connected layers; one of:
- `None`: no batch normalization layers.
- `shared`: use a single batch normalization layer for all tasks. Note that this can cause catastrophic forgetting.
- `independent`: use independent batch normalization layers for each task.
- **bias** (`bool`): Whether to use bias in the linear layer. Default `True`.
- **dropout** (`float` | `None`): The probability for the dropout layer. If `None`, this layer won't be used. Default `None`.
- **kwargs**: Reserved for multiple inheritance.
"""
super().__init__(
input_dim=input_dim,
hidden_dims=hidden_dims,
output_dim=output_dim,
gate=gate,
activation_layer=activation_layer,
batch_normalization=batch_normalization,
bias=bias,
dropout=dropout,
**kwargs,
)
# save these arguments for backup backbone initialization
self.input_dim: int = input_dim
r"""The input dimension of the AmnesiacHATMLP backbone network."""
self.hidden_dims: list[int] = hidden_dims
r"""The hidden dimensions of the AmnesiacHATMLP backbone network."""
self.output_dim: int = output_dim
r"""The output dimension of the AmnesiacHATMLP backbone network."""
self.activation_layer: nn.Module | None = activation_layer
r"""The activation layer of the AmnesiacHATMLP backbone network."""
self.batch_normalization: str | None = batch_normalization
r"""The way to use batch normalization after the fully-connected layers."""
self.bias: bool = bias
r"""Whether to use bias in the linear layer of the AmnesiacHATMLP backbone network."""
self.dropout: float | None = dropout
r"""The dropout probability of the AmnesiacHATMLP backbone network."""
self.backup_backbones: dict[int, MLP] = {}
r"""The backup backbone networks.
It has the same architecture as the main backbone network."""
def initialize_backup_backbone(
self,
unlearnable_task_ids: list[int],
) -> None:
r"""Initialize the backup backbone network for the current task. This is called when a new task is created.
**Args:**
- **unlearnable_task_ids** (`list[int]`): The list of unlearnable task IDs at current task `self.task_id`.
"""
unlearnable_task_ids = [
tid for tid in unlearnable_task_ids if tid != self.task_id
] # exclude current task, as we don't need backup backbone for current task
self.backup_backbones: dict[int, MLP] = {
unlearnable_task_id: MLP(
input_dim=self.input_dim,
hidden_dims=self.hidden_dims,
output_dim=self.output_dim,
activation_layer=self.activation_layer,
batch_normalization=self.batch_normalization,
bias=self.bias,
dropout=self.dropout,
)
for unlearnable_task_id in unlearnable_task_ids
}
def forward(
self,
input: Tensor,
stage: str,
s_max: float | None = None,
batch_idx: int | None = None,
num_batches: int | None = None,
cumulative_mask: dict[str, Tensor] | None = None,
test_task_id: int | None = None,
) -> tuple[Tensor, dict[str, Tensor], dict[str, Tensor]]:
r"""The forward pass for data from task `self.task_id`. Task-specific masks for `self.task_id` are applied to units (neurons) in each fully connected layer. During training, the backup backbone masked by cumulative mask is trained parallely.
**Args:**
- **input** (`Tensor`): The input tensor from data.
- **stage** (`str`): The stage of the forward pass; one of:
1. 'train': training stage.
2. 'validation': validation stage.
3. 'test': testing stage.
- **s_max** (`float`): The maximum scaling factor in the gate function. Doesn't apply to the testing stage. See Sec. 2.4 in the [HAT paper](http://proceedings.mlr.press/v80/serra18a).
- **batch_idx** (`int` | `None`): The current batch index. Applies only to the training stage. For other stages, it is `None`.
- **num_batches** (`int` | `None`): The total number of batches. Applies only to the training stage. For other stages, it is `None`.
- **cumulative_mask** (`dict[str, Tensor]` | `None`): The cumulative mask up to previous tasks. Applies only to the training stage. For other stages, it is `None`.
- **test_task_id** (`int` | `None`): The test task ID. Applies only to the testing stage. For other stages, it is `None`.
**Returns:**
- **output_feature** (`Tensor`): The output feature tensor to be passed into heads. This is the main target of backpropagation.
- **output_backup_feature** (`Tensor`): The output feature tensor from the backup backbone masked by cumulative mask. This is the parellel target of backpropagation.
- **mask** (`dict[str, Tensor]`): The mask for the current task. Keys (`str`) are the layer names and values (`Tensor`) are the mask tensors. The mask tensor has size (number of units, ).
- **activations** (`dict[str, Tensor]`): The hidden features (after activation) in each weighted layer. Keys (`str`) are the weighted layer names and values (`Tensor`) are the hidden feature tensors. This is used for continual learning algorithms that need hidden features. Although the HAT algorithm does not need this, it is still provided for API consistency for other HAT-based algorithms that inherit this `forward()` method of the `HAT` class.
"""
batch_size = input.size(0)
activations = {}
unlearnable_task_ids = self.backup_backbones.keys()
mask = self.get_mask(
stage=stage,
s_max=s_max,
batch_idx=batch_idx,
num_batches=num_batches,
test_task_id=test_task_id,
)
if self.batch_normalization:
fc_bn = self.get_bn(stage=stage, test_task_id=test_task_id)
x = input.view(batch_size, -1) # flatten before going through MLP
if stage == "train":
x_backup = {
unlearnable_task_id: input.view(batch_size, -1)
for unlearnable_task_id in unlearnable_task_ids
} # flatten for backup backbone
for layer_idx, layer_name in enumerate(self.weighted_layer_names):
# fully-connected layer first
x = self.fc[layer_idx](x)
if stage == "train":
for unlearnable_task_id in unlearnable_task_ids:
backup_backbone = self.backup_backbones[unlearnable_task_id]
x_backup[unlearnable_task_id] = cumulative_mask[
layer_name
] * backup_backbone.fc[layer_idx](x_backup[unlearnable_task_id]) + (
1 - cumulative_mask[layer_name]
) * self.fc[
layer_idx
](
x_backup[unlearnable_task_id]
) # apply cumulative mask to backup backbone
if self.batch_normalization:
# batch normalization second
x = fc_bn[layer_idx](x)
if stage == "train":
for unlearnable_task_id in unlearnable_task_ids:
x_backup[unlearnable_task_id] = fc_bn[layer_idx](
x_backup[unlearnable_task_id]
)
# apply the mask to the parameters second
x = x * mask[f"fc/{layer_idx}"]
if stage == "train":
for unlearnable_task_id in unlearnable_task_ids:
x_backup[unlearnable_task_id] = (
x_backup[unlearnable_task_id] * mask[f"fc/{layer_idx}"]
)
# activation function third
if self.activation:
x = self.fc_activation[layer_idx](x)
if stage == "train":
for unlearnable_task_id in unlearnable_task_ids:
x_backup[unlearnable_task_id] = self.fc_activation[layer_idx](
x_backup[unlearnable_task_id]
)
activations[layer_name] = x # store the hidden feature
# dropout last
if self.dropout:
x = self.fc_dropout[layer_idx](x)
if stage == "train":
for unlearnable_task_id in unlearnable_task_ids:
x_backup[unlearnable_task_id] = self.fc_dropout[layer_idx](
x_backup[unlearnable_task_id]
)
output_feature = x
if stage == "train":
output_backup_feature = x_backup
return output_feature, output_backup_feature, mask, activations
else:
return output_feature, mask, activationsclass WSNMaskMLP(MLP, WSNMaskBackbone): r”““WSN (Winning Subnetworks, 2022) masked multi-layer perceptron (MLP).
[WSN (Winning Subnetworks, 2022)](https://proceedings.mlr.press/v162/kang22b/kang22b.pdf) is an architecture-based continual learning algorithm. It trains learnable parameter-wise importance and selects the most important $c\%$ of the network parameters to be used for each task.
MLP is a dense network architecture with several fully connected layers, each followed by an activation function. The last layer connects to the CL output heads.
The mask is applied to the weights and biases in each fully connected layer. The mask is generated from the parameter-wise score and the gate function.
"""
def __init__(
self,
input_dim: int,
hidden_dims: list[int],
output_dim: int,
activation_layer: nn.Module | None = nn.ReLU,
bias: bool = True,
dropout: float | None = None,
**kwargs,
) -> None:
r"""Construct and initialize the WSN-masked MLP backbone network with task embeddings.
**Args:**
- **input_dim** (`int`): The input dimension. Any data need to be flattened before entering the MLP.
- **hidden_dims** (`list[int]`): List of hidden layer dimensions. It can be an empty list, which means a single-layer MLP, and it can be as many layers as you want. Note that it doesn't include the last dimension, which we take as the output dimension.
- **output_dim** (`int`): The output dimension that connects to CL output heads.
- **activation_layer** (`nn.Module` | `None`): Activation function of each layer (if not `None`). If `None`, this layer won't be used. Default `nn.ReLU`.
- **bias** (`bool`): Whether to use bias in the linear layer. Default `True`.
- **dropout** (`float` | `None`): The probability for the dropout layer. If `None`, this layer won't be used. Default `None`.
- **kwargs**: Reserved for multiple inheritance.
"""
# init from both inherited classes
super().__init__(
input_dim=input_dim,
hidden_dims=hidden_dims,
output_dim=output_dim,
activation_layer=activation_layer,
batch_normalization=False,
bias=bias,
dropout=dropout,
**kwargs,
)
# construct the parameter score for each weighted layer
for layer_idx in range(self.num_fc_layers):
full_layer_name = f"fc/{layer_idx}"
layer_input_dim = (
input_dim if layer_idx == 0 else hidden_dims[layer_idx - 1]
)
layer_output_dim = (
hidden_dims[layer_idx] if layer_idx != len(hidden_dims) else output_dim
)
self.weight_score_t[full_layer_name] = nn.Embedding(
num_embeddings=layer_output_dim,
embedding_dim=layer_input_dim,
)
self.bias_score_t[full_layer_name] = nn.Embedding(
num_embeddings=1,
embedding_dim=layer_output_dim,
)
def forward(
self,
input: Tensor,
stage: str,
mask_percentage: float,
test_mask: tuple[dict[str, Tensor], dict[str, Tensor]] | None = None,
) -> tuple[Tensor, dict[str, Tensor], dict[str, Tensor], dict[str, Tensor]]:
r"""The forward pass for data from task `self.task_id`. Task-specific masks for `self.task_id` are applied to units (neurons) in each fully connected layer.
**Args:**
- **input** (`Tensor`): The input tensor from data.
- **stage** (`str`): The stage of the forward pass; one of:
1. 'train': training stage.
2. 'validation': validation stage.
3. 'test': testing stage.
- **mask_percentage** (`float`): The percentage of parameters to be masked. The value should be between 0 and 1.
- **test_mask** (`tuple[dict[str, Tensor], dict[str, Tensor]]` | `None`): The binary weight and bias masks used for testing. Applies only to the testing stage. For other stages, it is `None`.
**Returns:**
- **output_feature** (`Tensor`): The output feature tensor to be passed into heads. This is the main target of backpropagation.
- **weight_mask** (`dict[str, Tensor]`): The weight mask for the current task. Keys (`str`) are the layer names and values (`Tensor`) are the mask tensors. The mask tensor has the same size (output features, input features) as the weight.
- **bias_mask** (`dict[str, Tensor]`): The bias mask for the current task. Keys (`str`) are the layer names and values (`Tensor`) are the mask tensors. The mask tensor has the same size (output features, ) as the bias. If the layer doesn't have a bias, it is `None`.
- **activations** (`dict[str, Tensor]`): The hidden features (after activation) in each weighted layer. Keys (`str`) are the weighted layer names and values (`Tensor`) are the hidden feature tensors. This is used for continual learning algorithms that need hidden features for various purposes.
"""
batch_size = input.size(0)
activations = {}
weight_mask, bias_mask = self.get_mask(
stage,
mask_percentage=mask_percentage,
test_mask=test_mask,
)
x = input.view(batch_size, -1) # flatten before going through MLP
for layer_idx, layer_name in enumerate(self.weighted_layer_names):
weighted_layer = self.fc[layer_idx]
weight = weighted_layer.weight
bias = weighted_layer.bias
# mask the weight and bias
masked_weight = weight * weight_mask[f"fc/{layer_idx}"]
if bias is not None and bias_mask[f"fc/{layer_idx}"] is not None:
masked_bias = bias * bias_mask[f"fc/{layer_idx}"]
else:
masked_bias = None
# do the forward pass using the masked weight and bias. Do not modify the weight and bias data in the original layer object or it will lose the computation graph.
x = nn.functional.linear(x, masked_weight, masked_bias)
if self.activation:
x = self.fc_activation[layer_idx](x) # activation function third
activations[layer_name] = x # store the hidden feature
if self.dropout:
x = self.fc_dropout[layer_idx](x) # dropout last
output_feature = x
return output_feature, weight_mask, bias_mask, activations