The metrics in deep learning are sometimes confusing, not to mention that in continual learning with sequential tasks. This post provides a guide for all the metrics we might encounter in continual learning systems.
Categories of Metrics
Deep learning consists of training, validation and testing process, therefore have:
- Training metrics: recorded and calculated from training process, used to monitor the performance and state of the model during training.
- Validation metrics: recorded and calculated from validation process, used to select the best model among the checkpoints during training.
- Test metrics: recorded and calculated from the testing process. It is the final result to get to evaluate the model.
Deep learning metrics can also be divided into two categories by the range they measure:
- Metrics of a batch:. Basic units of metrics. They can be accessed in real-time.
- Metrics of an epoch: accumulated and averaged from metrics of batches.
- For training epoch, it reflects a phased result of the model training. Note that it is not accumulated on the same model as the model keeps updating during training.
- For validation and test epochs, this is the final result to get, which can be considered as metrics of the task, if you think the process as a task. Note that since the model is fixed and put into evaluation mode now, it is accumulated on the same model, i.e. the model to be evaluated.
Continual learning is actually an extension to the one-task deep learning, as it is concerned with a sequence of tasks. In this case, we have a higher level of metrics:
- Metrics over tasks: accumulated and averaged from metrics of tasks. It only applied to test metrics. It reflects the overall performance over the sequence of tasks, which is what continual learning cares about.
List of Metrics in Continual Learning
We now go through the metrics in continual learning one by one, starting with the metrics for one task and then for the metrics over tasks:
Metrics for one task (which is nothing special from one-task deep learning):
- Performance of Training Batch
- Performance of Training Epoch
- Validation Performance after Training Epoch
- Learning Curve
- Test Performance of Task
Metrics over tasks:
- Test Performance of Previous Tasks
- Average Test Performance Over All Tasks
- Other Metrics Over All Tasks
Note that we limit our scope at classification problem, which involves performance metrics like accuracy and classification loss (cross-entropy loss).
Performance of Training Batch
Definition 1 (Performance of Training Batch) The average performance of the current model (after trained on the batch) over the batch of data.
It is the most basic metrics, which can be accumulated to form many other metrics. Suppose we have done the forward pass and backward pass of a batch of data \((\mathbf{X}_{\text{batch}}, Y_{\text{batch}}) = \{(\mathbf{x}_i, y_i)\}_{i=1}^{B}\), we can get the loss and accuracy of the batch:
\[L_{\text{batch}} = \frac1B \sum_{i=1}^B l(f(\mathbf{x}_i), y_i)\]
\[a_{\text{batch}} = \frac1B \sum_{i=1}^B I(\text{prediction}(f(\mathbf{x})_i) = y_i)\]
It is the key to monitor the performance and state of the model in real-time during training, which can help identify following issues:
- Tell overfitting or underfitting from its convergence behaviour;
- Tell if the learning rate too high or low;
- The monitor to implement early stopping.
This metric can be very handy to get after the forward pass of the training batch. Common practices are to log it to the progress bar or kind of dashboards (like TensorBoard) to monitor in real time.
There is a consistency problem to monitor this metric: it is calculated from different batches, which doesn’t provide a fair comparison if we want to monitor how the model is evolving. Therefore, we often find the curve of this metric is very noisy. Some smoothing techniques can be applied to make it more readable. Some would instead choose a cumulative average over batches:
\[L = \frac1{B_1 + B_2 +\cdots} (B_1 \cdot L_{\text{batch1}} + B_2 \cdot L_{\text{batch2}} + \cdots )\]
This gives a more stable curve and reflects the entire training process having been through so far, and is more often used for monitoring.
In the ideal case, the dataloader often shuffles the data to generate batches, so the training batches can be roughly treated as evenly distributed.
Performance of Training Epoch
Definition 2 (Performance of Training Epoch) The average performance of the current model (after trained through the epoch) over an epoch of training data, i.e. the entire training data.
This metric provides a more comprehensive view of the model performance during the training process.
If we stick to the definition, we have to fix the model at the end of the epoch and go through the entire training data once again to calculate this metric. However, we can afford another entire training process by no means just to get a single metric!
In practice, we use the cumulative average (mentioned in Note 1) of the performance of training batches in the epoch to approximate this metric. The difference is this measures the trajectory of model during the training process instead of the model state at the end of the epoch.
To implement it, you can maintain a cumulative counter and a cumulative loss / accuracy in the training loop.
As an implementation tip, you can maintain a cumulative counter and a cumulative performance variable in the training loop. Each time after a batch training, add to the cumulative counter and the cumulative performance variable. The division of the two gives the cumulative average performance of the training process so far. At the end of the epoch, it exactly turns to the performance of training epoch.
Remember to reset the two at the start of next epoch, so that you can get the performance of another training epoch.
Validation Performance after Training Epoch
Definition 3 (Validation Performance) The average performance of the current model (after trained through the epoch) over the validation data. Validation performance only refers to this, i.e. validation performance after training epoch.
The validation process is to test the model trained so far during the training process without using the testing data. It typically happens after each training epoch, which marks a complete period of training. (Validation after each training batch would cost too much. ) Its goal is to get a validation performance to select the best model among the epoch checkpoints during training.
The validation dataset is still fairly huge amount of data, so the process needs to go through the validation data with batches and accumulate the performance of validation batches (the same way as Note 1). Note that this only need to be done once, i.e., 1 epoch. Unlike the approximation stuff we discussed in Section 2.2, this cumulative average performance of the validation process is exactly the validation performance because the model is fixed between the batches.
The validation performance above is the only thing that the validation process is about. You can see that we don’t talk about the performance of validation batch. That’s because it’s just a tool or intermediate variable to get the validation performance, with no value to be monitored.
Learning Curve
We now have got the performance of training epoch and validation performance after this epoch. We can plot them, which is what we call as learning curve.
(Placeholder: I am working on to get a learning curve plot from my project.)
The x-axis of learning curve represents the progress of training process. It is usually epoch-wise (as we discuss above, batch-wise costs just too much for the validation). The y-axis represents the performance of the model on two datasets: training dataset and validation dataset, shown in two curves.
Learning curve is also a monitor of the training process. If we only look at the curve for training dataset, it is exactly the monitor – performance of training that we discussed above. Since it’s a comparsion thing between training and validation dataset, it mainly tells the generalisation ability of the model. I am sure you have learned a lot about this through deep learning tutorials, so I won’t go further here.
Test Performance of Task
Test performance is the same thing as validation performance, but on the testing dataset, for the final model. It also has to be calculated in batches, but only 1 epoch, just to accumulate and get a number.
But remember, we are talking about continual learning here, which involves a sequence of tasks. This is only for a single task, let’s assume it’s task \(t\). We would rather call it as test performance of task to be more specific.
Definition 4 (Test Performance of Task \(t\)) The average performance of the final model (after training task \(t\)) over the testing data of task \(t\).
Now we move to the metrics over tasks.
Test Performance of Previous Tasks
After training task \(t\), we can not only test the model on the testing dataset of task \(t\), but also on the testing datasets of previous tasks \(\tau = 1,2,\cdots,t-1\). These are important metrics in continual learning telling how well the model has preserved the knowledge of each previous task. The testing process in continual learning for a task \(t\) is not testing task \(t\) but testing task \(1,2,\cdots,t\).
The metrics are calculated in the same way as the test performance of task \(t\), but on the testing datasets of previous tasks. We take test accuracy as an example, and denote \(a_{\tau, t} (\tau \leq t)\) as the accuracy of the model after learning task \(t\) on task \(\tau\) testing dataset. If we go through all the combinations, it forms an lower triangular matrix of performance metrics:
\[ \begin{array}{cccc} a_{1,1} & a_{1,2} & a_{1,3} & \cdots \\ & a_{2,2} & a_{2,3} & \cdots \\ & & a_{3,3} & \cdots \\ \vdots & \vdots & \vdots & \ddots \\ \end{array} \]
This matrix is essential for the metrics over tasks that we’re going to discuss below.
We saw the testing process on previous tasks is task-wise, but there are occasions that this testing process is epoch-wise (even batch-wise), i.e., testing the model after each training epoch (batch) on the testing datasets of previous tasks. You can find an example in the EWC paper:
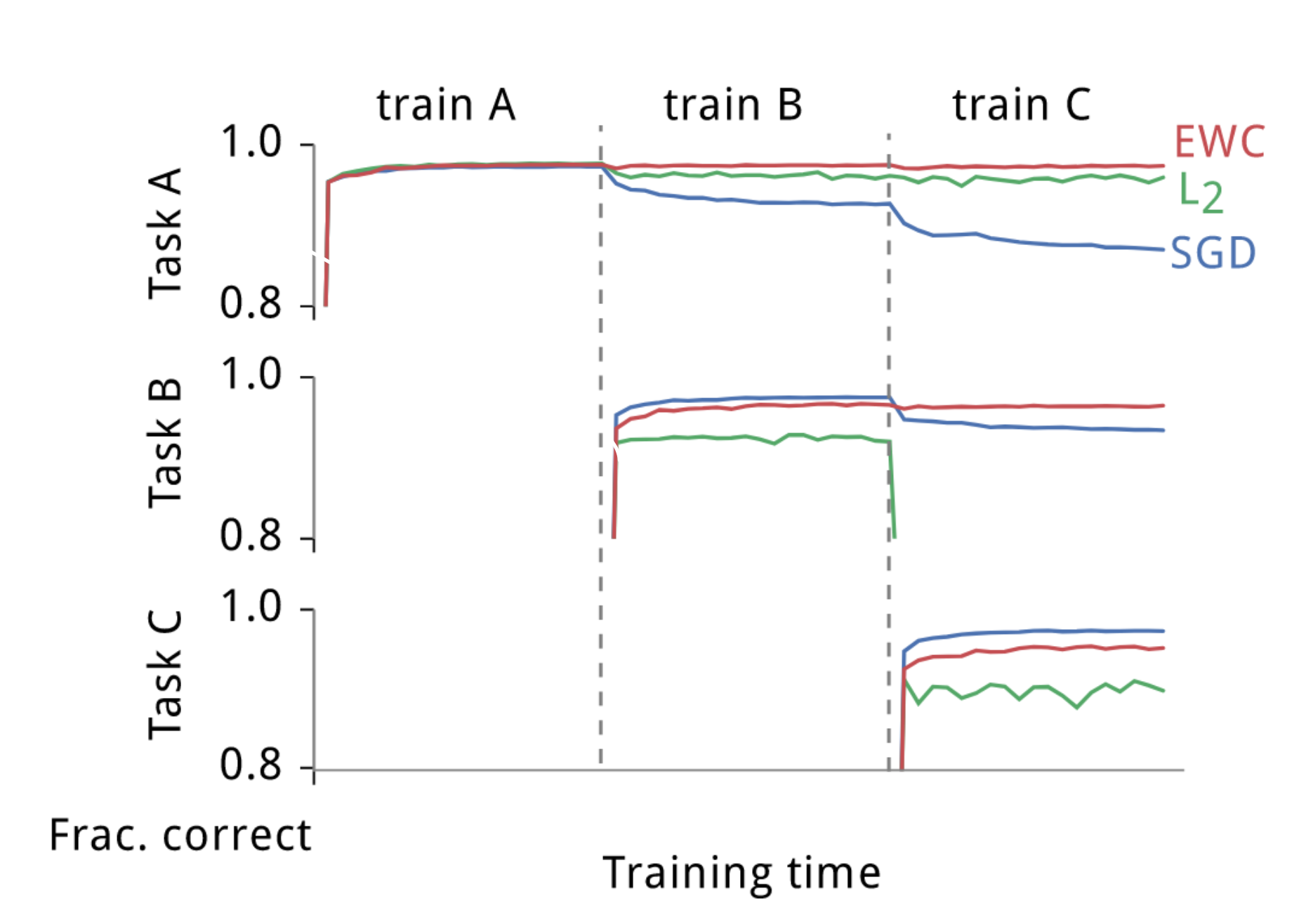
This costs way too much and is not the standard practice in continual learning protocol. That paper only used it for their own analysis.
Average Test Performance Over All Tasks
The metric matrix above seems messy, and if we want to just get a single number to represent the overall performance of the model over the tasks, we can simply aggregate the metrics in a certain way, like averaging:
Definition 5 (Average Accuracy, AA) The average test accuracy of the model over all the tasks till task \(t\):
\[\mathrm{AA}_t=\frac{1}{t} \sum_{\tau=1}^t a_{\tau, t}\]
This is the most straightforward metric to represent the overall performance of the model in continual learning. It is the most common and important metric to report in continual learning papers.
This metric can be plot as a curve over \(t\), which is also commonly seen as the main result plot in continual learning papers:
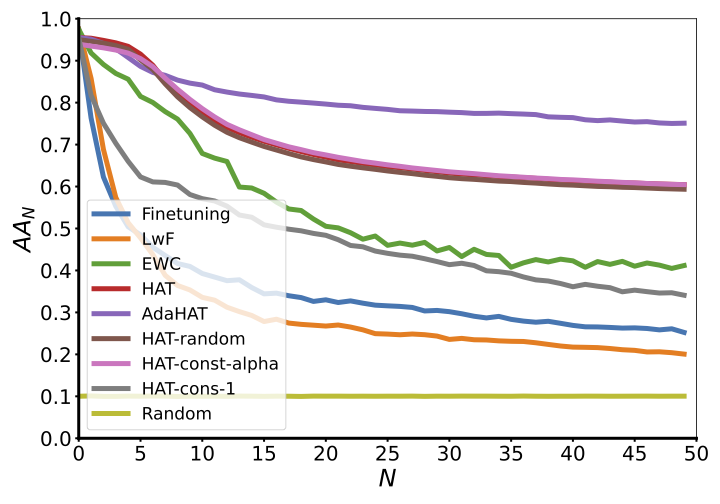
Other Metrics Over All Tasks
We can use different aggregation formulas to get other single-number metrics over all tasks. They reflect different aspects of the model in continual learning.
First, we define some reference metrics:
- \(a^J_{\tau, t}\): the accuracy on dataset \(D^t\) of a randomly-initialized reference model jointly trained on \(\cup_{\tau=1}^t D^\tau\);
- \(a^I_\tau\): the accuracy of a randomly-initialized reference model independently trained on \(D^\tau\);
- \(a^R_\tau\): the accuracy of a random stratified model.
The following metrics are mostly aggregated from the lower triangular matrix of metrics \(a_{\tau, t}\ (\tau \leq t)\) and reference metrics.
Definition 6 (Forgetting Ratio, FR) \[ \mathrm{FR}_t=\frac{1}{t} \sum_{\tau=1}^t \frac{a_{\tau, t}-a^R_{\tau}}{a^J_{\tau, t}-a^R_{\tau}} - 1 \]
This metric first showed in HAT paper. It acts the same way as the AA metric, but it is normalised by the reference model performance. It tells how much the model has forgotten the previous tasks.
Definition 7 (Backward Transfer, BWT) \[ \mathrm{BWT}_t=\frac{1}{t-1} \sum_{\tau=1}^{t-1}\left(a_{\tau, t}-a_{\tau, \tau}\right) \]
Definition 8 (Forward Transfer, FWT) \[ \mathrm{FWT}_t=\frac{1}{t-1} \sum_{\tau=2}^t\left(a_{\tau, \tau}-a^I_\tau\right) \]
These two metrics are commonly used for measuring stability and plasticity when talking about the stability-plasticity trade-off in continual learning. Find detailed explanation in my CL beginner’s guide.
Resources
My CLArena project has implemented all these metrics. You can check out the API reference and source code for more details.