My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Recurrent Neural Network (RNN) is a type of neural network designed for processing sequential data. Unlike conventional neural networks that take single input to single output, RNNs have connections that loop back on themselves (which is recurrent), allowing accumulating information over the sequential data iteratively.
Because RNNs can naturally handle variable-length sequential data. If we feed sequential data into conventional neural networks, we have to fix the length of the input sequence, either by truncating longer sequences or padding shorter ones. This can lead to loss of information or introduce noise.
The RNN processes sequences of data.
Inputs:
- A sequence of input data
Outputs:
- A sequence of outputs
Please note, a RNN can receive any length of sequence. The length
The vanilla RNN architecture is illustrated as follows:
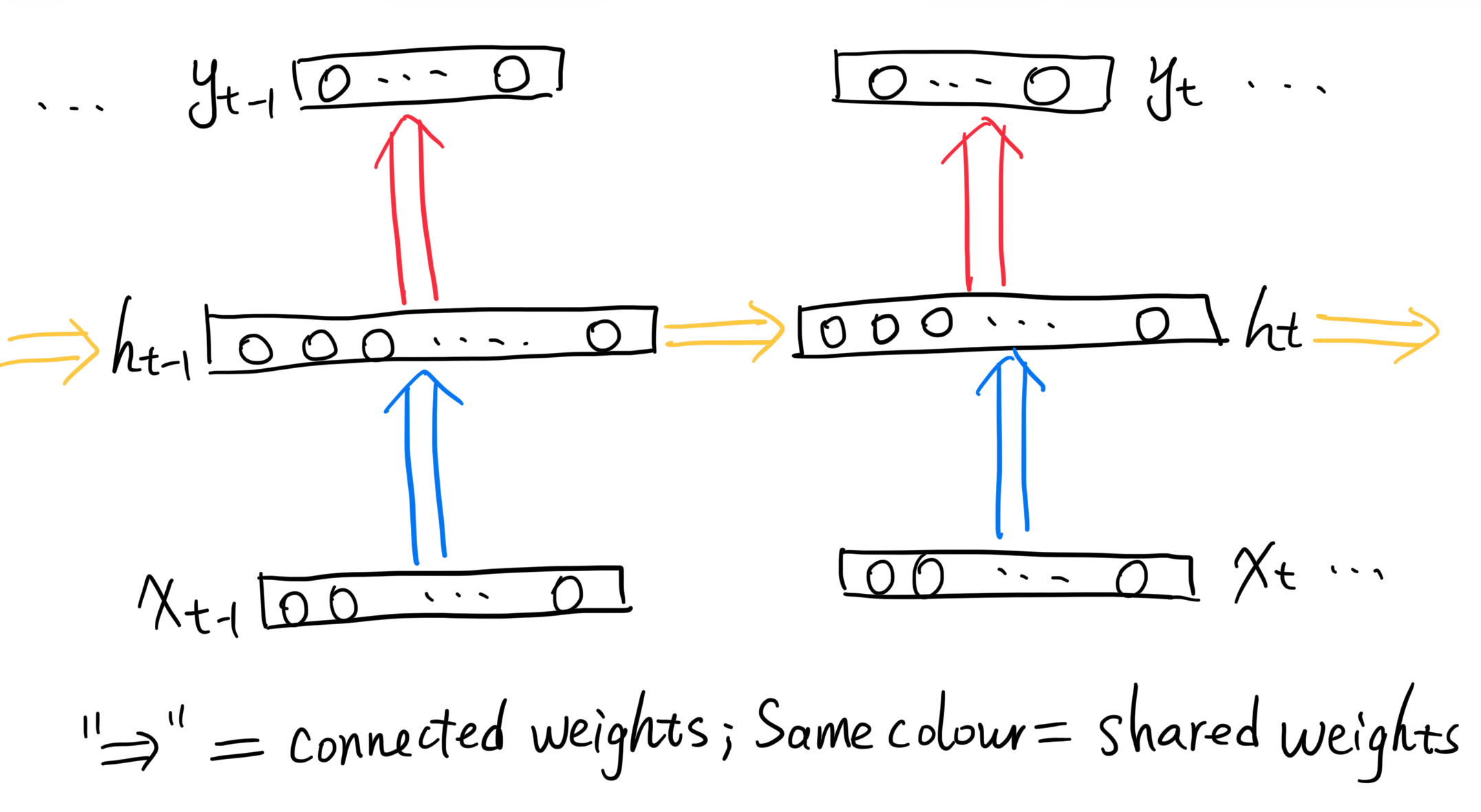
The blue and yellow arrows are the connections between the input and hidden states:
The red arrow is the connection between the hidden state and output:
These weights are shared across all time steps, which is a key feature of RNNs that allows them to generalise across different sequence lengths.
The forward pass of RNN involves iterating through each time step of the input sequence and updating the hidden state and output at each step, instead of processing the entire sequence at once.
- Hidden state initialization: Set the initial hidden state
- For each time step
- Compute the new hidden state
- Compute the output
- Compute the new hidden state
The hidden state
The loss function of RNN is the average of the loss at each time step:
This is neither calculated and backpropagated at once, but step by step through time, which is called Backpropagation Through Time (BPTT):
- For each time step
- The forward pass computes the loss
- The backward pass computes the gradients
- The forward pass computes the loss
- The total gradient is the sum of the gradients from each time step:
RNNs are commonly used for tasks involving sequential data, such as text, speech, and time series data. Please note when we say sequential data, it usually refers to variable-length sequential data because the fixed-length sequential data can be essentially regarded as the conventional input data.
There are many tasks on various kinds of sequential data. The RNN can generally be used for 3 types of tasks, each having many applications:
- Many to many: The input is a sequence, and the output a sequence of equal length.
- POS tagging: Given a sequence of words (a sentence), predict the sentiment (positive, negative, neutral) for each word in the sequence.
- Machine translation: Given a sequence of words (a sentence) in one language, predict the sequence of words in another language. Machine translation is a sequence-to-sequence task where the input and output sequences can have different lengths, so this is not a good practice example of many to many task. Please check autoregressive prediction below or my article about encoder-decoder.
- Many to one: The input is a sequence, and the output is a single value. In RNN, we can simply take the last output
- Sentiment classification: Given a sequence of words (a sentence), predict the sentiment (positive, negative, neutral) for the sequence.
- Speech recognition: Given a sequence of audio features, predict the spoken word or phrase.
- Autoregressive prediction: The input is a sequence, and the output is a single value. The output are then appended to the input, and the model is used to predict the next value in the sequence. This can be repeated to generate a sequence of outputs.
- Stock price prediction: Given a sequence of historical stock prices, predict the stock price for the time steps in the future. This is a regression task for sequential data.
- Machine translation can also be designed as an autoregressive prediction task.
Vanilla RNNs have several limitations, including:
- Vanishing / exploding gradients: During BPTT, if the sequence is long, the gradients backpropagated through many time steps can become very small (vanish) or very large (explode), making it difficult to train the model effectively.
- Short-range dependencies: The hidden state has limited capacity to store information as it is overwritten at each time step, making it difficult to capture long-range dependencies in the sequence.
These limitations have led to the development of more advanced RNN architectures, such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which are designed to address these issues.