This series simply answers questions about AI concepts, serving as a quick reference for both you and me at all levels.
AI Concept Takeaway series
research
general deep learning
Published
September 28, 2025
Modified
October 21, 2025
My takeaway series follow a Q&A format to explain AI concepts at three levels:
TipConceptual Level
Anyone with general knowledge can understand them.
WarningImplementation Level
For anyone who wants to dive into the code implementation details of the concept.
ImportantMathematical Level
For anyone who wants to understand the mathematics behind the technique.
TipWhat is Encoder-Decoder?
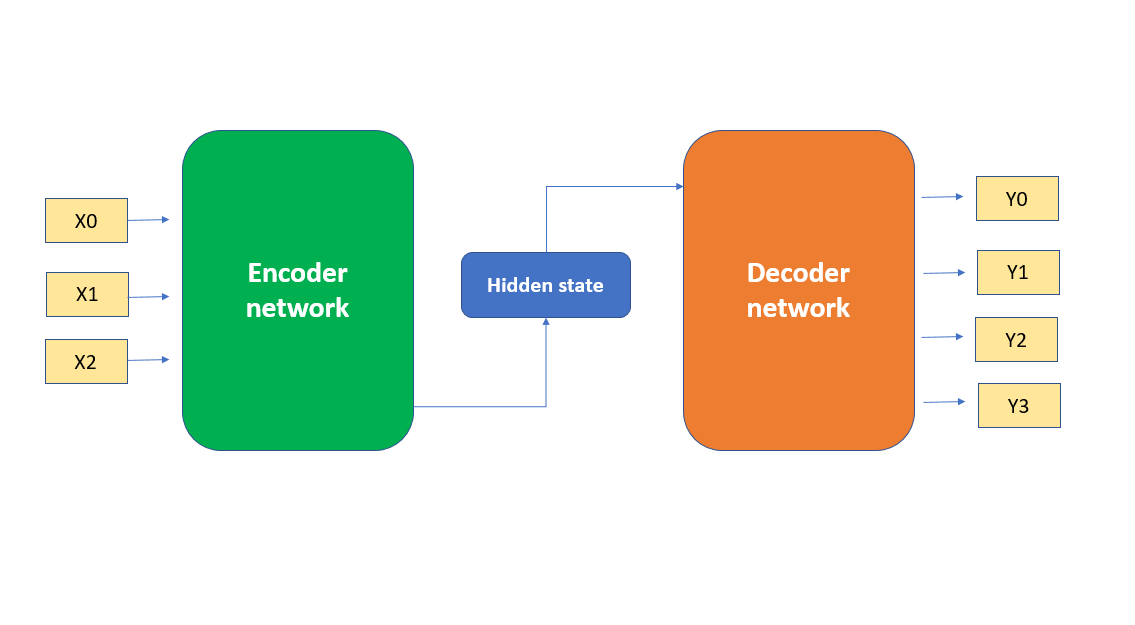
The Encoder-Decoder architecture is a neural network design pattern. It doesn’t refer to a specific type of neural network but rather a framework that can be implemented using various types of neural networks.
The encoder-decoder architecture consists of encoder and decoder, both of which are neural networks. By its name, any neural network that can process input into a encoded representation and then decode that representation back into a desired output format can be considered an encoder-decoder architecture. However, in the context of deep learning research, it refers to the proposed architecture after 2014 used for sequence-to-sequence tasks, such as machine translation, text summarization, and image captioning.
TipWho proposed Encoder-Decoder? What is the background?
The encoder-decoder architecture was popularized by a 2014 paper (Sutskever, Vinyals, and Le 2014) from Google. The background was the need to handle sequence-to-sequence tasks in NLP, such as machine translation, where the input and output sequences can have different lengths. It is then advanced by (cho2014learning?) who proposed the attention mechanism to improve the performance of the encoder-decoder architecture.
TipHow neural networks are used in encoder-decoder?
Since the input receives a sequence of data, the encoder should a type of neural network that can handle sequential data, such as RNN, LSTM. In later years, Transformer introduces the self-attention mechanism, which is more powerful than RNN and LSTM. The entire Transformer is an encoder plus decoder.
TipWhat are the common encoder-decoder architectures?
The common encoder-decoder architectures include:
RNN/LSTM-based Encoder-Decoder: The original architecture proposed in the 2014 paper (Sutskever, Vinyals, and Le 2014), using RNNs or LSTMs for both encoder and decoder.
Transformer: Transformer (Vaswani et al. 2017) is an encoder-decoder architecture, where the encoder and decoder are both composed of layers with self-attention mechanisms.
ImportantWhat are the inputs and outputs of encoder and decoder?
Following the original meaning of encoder-decoder architecture, both encoder and decoder can receive any kind of data as input and output.
For the context of deep learning, the encoder-decoder architecture is designed for sequence-to-sequence tasks, where the input and output are both variable-length sequences.
A sequence of input data of any length, where is the length of the input sequence. The index is called the time step in the sequence.
Encoder output:
A fixed-size context vector that summarizes the information from the entire input sequence. This context vector is passed to the decoder.
Decoder input:
The context vector from the encoder.
A special start-of-sequence data <SOS> to indicate the beginning of the output sequence.
Decoder output:
Could be a sequence of output data of any length, where is the length of the output sequence, which can be different from . The last output is a special end-of-sequence data <EOS> to indicate the end of the output sequence.
Could be a single output data , which can feed itself back to the input sequence as to generate the next value step by step until it produces the end-of-sequence <EOS>. This is called autoregression.
Anyway, the final output can be a sequence of data.
TipWhat is the difference between encoder-decoder and autoregression?
Encoder-decoder and autoregression can both receive variable sequences of data as input. However, the model in autoregression can only output one value at a time, but it can autoregressively feed the previously generated output back into itself to generate the next value step by step until it produces the final output. Therefore, autoregression is more of a strategy to extend many-to-one models to output variable-length output sequences.
The decoder in the encoder-decoder architecture can be either many-to-many or many-to-one. If the decoder is many-to-one, it can use autoregression to generate variable-length output sequences. Transformer decoder is an example of many-to-one decoder that uses autoregression to generate output sequences, see AI concept takeaway: Transformer.
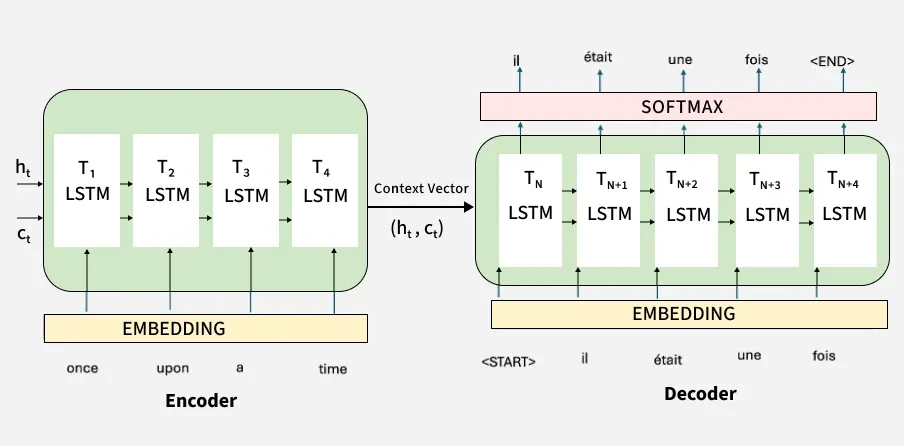
ImportantWhat is the architecture of vanilla Encoder-Decoder?
The vanilla Encoder-Decoder architecture uses RNN or LSTM for both encoder and decoder. For example, in LSTM-based encoder-decoder:
Vanilla encoder-decoder architecture using LSTMs. Source: GeeksforGeeks
The encoder LSTMs process the input sequence and use the final hidden state and cell state of the encoder as the context vector. The decoder LSTMs take this context vector as their initial hidden state and cell state to generate the output sequence step by step until they produce the end-of-sequence <EOS>.
TipWhat are the applications of encoder-decoder?
The encoder-decoder architecture is used in sequence-to-sequence tasks, including:
Machine Translation: Translating text from one language to another, e.g., English to French.
Text Summarization: Generating a concise summary of a longer text document.
Image Captioning: Generating descriptive captions for images by encoding image features and decoding them into text.
Speech Recognition: Converting spoken language into written text.
Sutskever, Ilya, Oriol Vinyals, and Quoc V Le. 2014. “Sequence to Sequence Learning with Neural Networks.”Advances in Neural Information Processing Systems 27.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.”Advances in Neural Information Processing Systems 30.