My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Long Short-Term Memory (LSTM) is a type of advanced recurrent neural network (RNN) architecture. It is designed to better capture long-range dependencies in sequential data.
The LSTM is basically an enhanced version of the vanilla RNN, with a more complex internal structure to manage information flow:
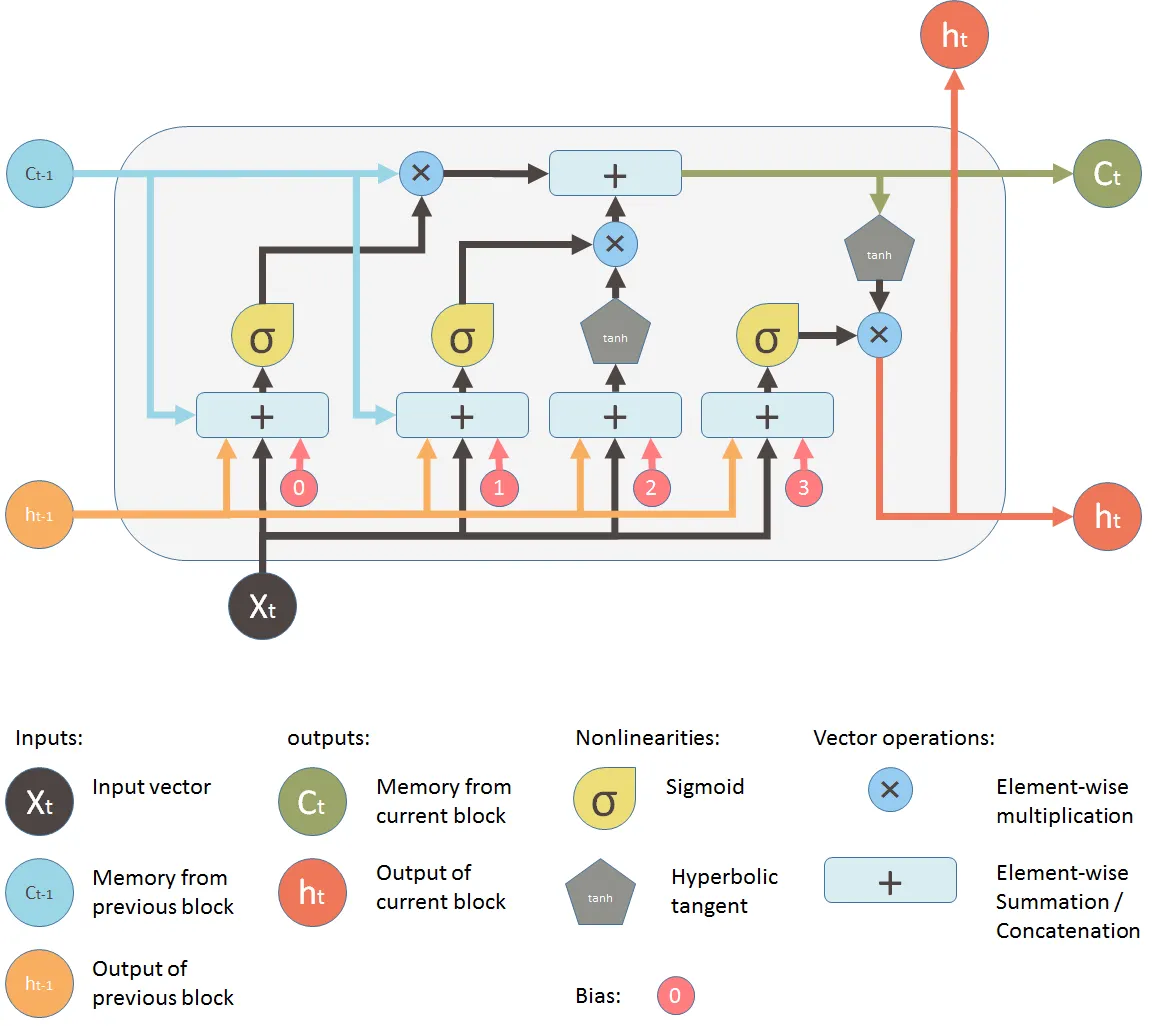

The
Unlike the vanilla RNN unit that directly updates the hidden state
- The hidden state
- The candidate cell state
Anyway, LSTM is a complex manual design by researchers to solve the problems of vanilla RNN. It is not easy to remember all the details.
LSTM has both long-term and short-term memory capabilities. Long-term memory is represented by the cell state
Vanilla RNN suffers from the vanishing / exploding gradient problem (see this article), which makes the model hard to train when the sequence is long. That is because the hidden state
However, in LSTM, the hidden state
Secondly, the vanilla RNN can only capture short-range dependencies (see this article). LSTM, as the name suggests, can capture both long-range and short-range dependencies in the sequence (see the above question), better than vanilla RNN.