My takeaway series follow a Q&A format to explain AI concepts at three levels:
The Concept of Activation Function
The activation function is attached to each neuron in a neural network. The neuron receives a weighted sum of inputs from the previous layer, and the activation function processes this sum to produce an output:
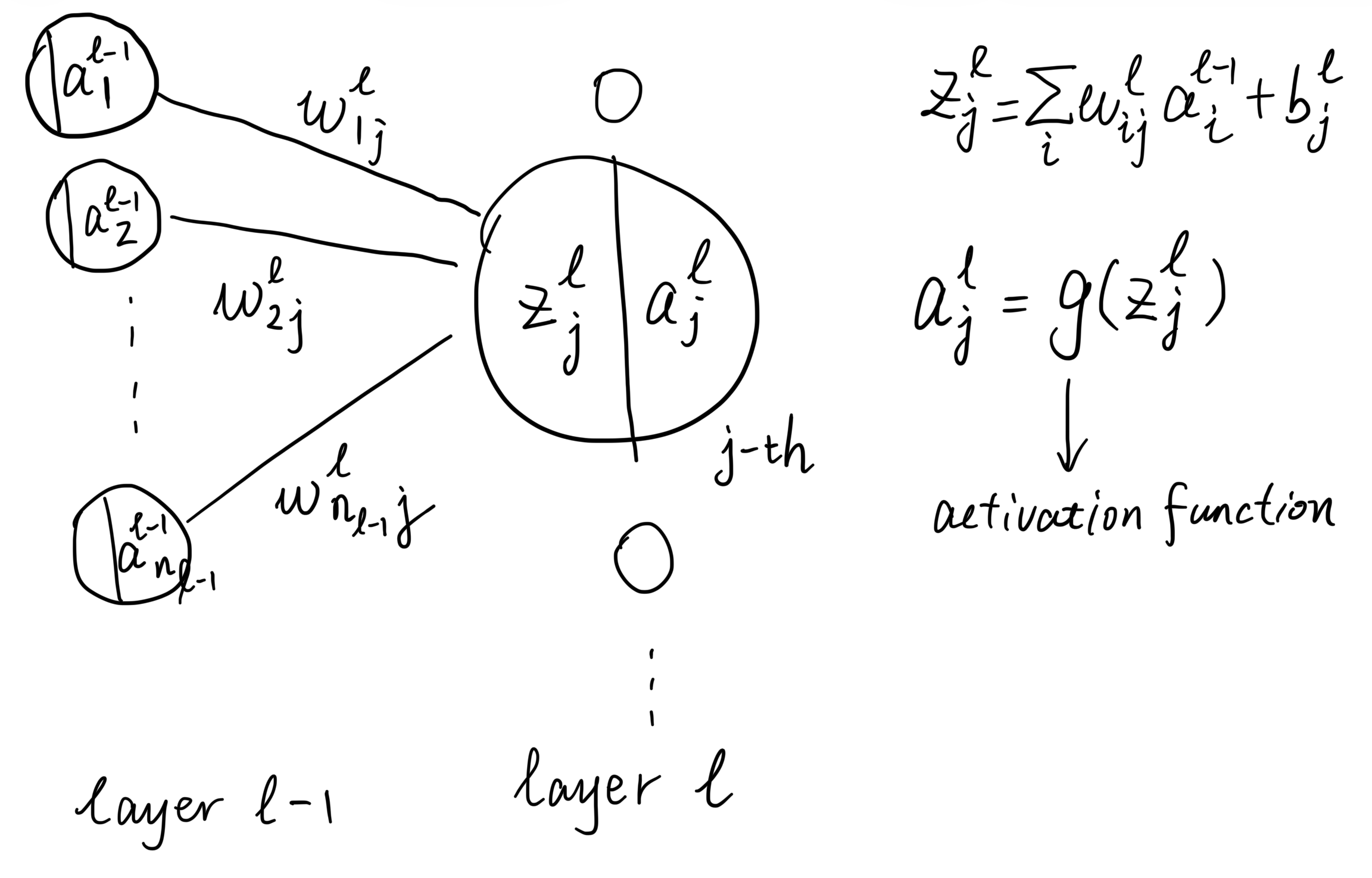
For the activation function \(g(\cdot)\) on the \(j\)-th neuron in the layer \(l\), the input:
- The weighted sum of inputs to the neuron: \(z_j^l = \sum_{i} w_{ij}^l a_i^{l-1} + b_j^l\).
Output:
- The activated output of the neuron: \(a_j^l = g(z_j^l)\)
Activation Functions
Common activation functions include:
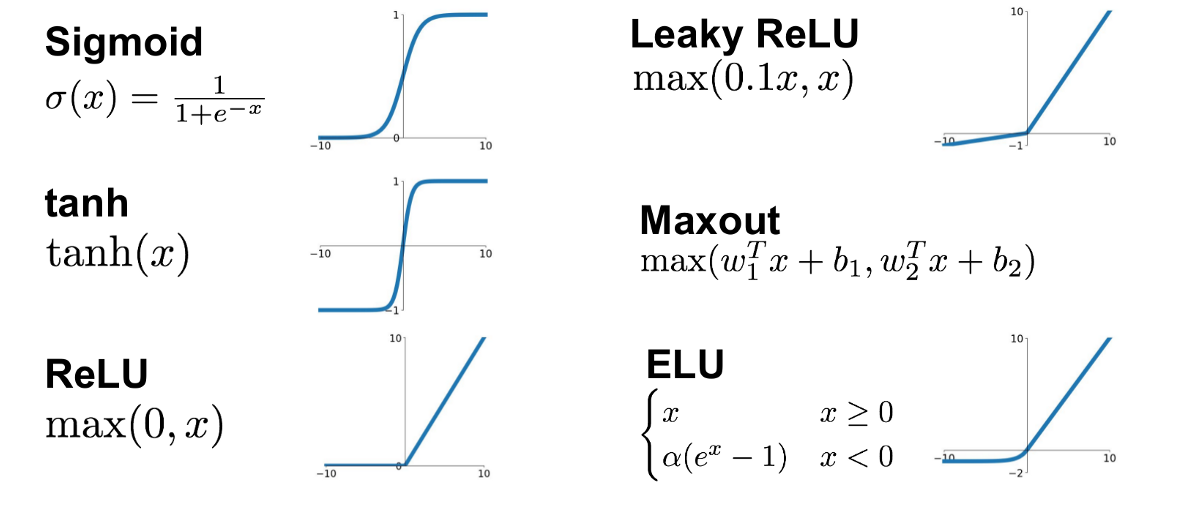
Sigmoid
From the computation graph of neural network, we can see that the path from the loss to a parameter (such as \(w^{L-1}_{12}\) in the example) includes the \(z\) to the parameter \(\frac{\partial z_2^{L}}{\partial w^{L-1}_{12}}\) at last. This term is the activation value, in this example \(a_1^{L-1}\). That is, the gradient of a parameter is proportional to the activation value of the neuron in the previous layer.
Suppose the activation function of the previous layer is Sigmoid, whose output is always positive. Then, for all parameters connecting to a neuron in the current layer (i.e., \(w_{ij}^l\) with fixed \(j\) and varying \(i\)), their gradients will have the same sign.
As a result, the parameters are divided into groups. For the parameters in the same group, they will always be updated in the same direction (either all increase or all decrease). This limits the freedom of parameter updates.
We illustrate a group in a 2D space below. Since the gradients have the same sign, the parameters will be updated either to the top-right or bottom-left. If the optimal solution happens to be the bottom-right direction (which is more likely in high-dimensional space), the zig-zag phenomenon occurs.
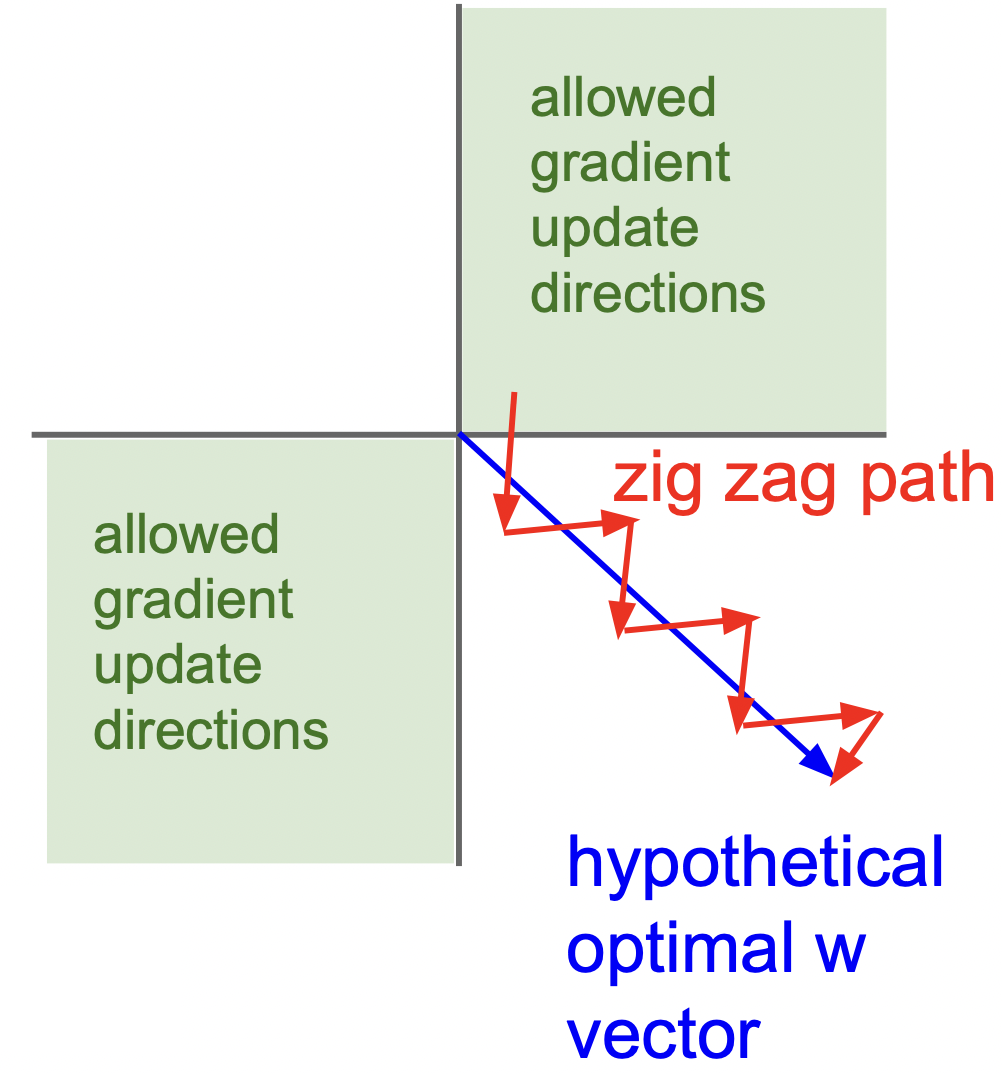
The optimal solution can be reached much faster if the parameters can be updated in the bottom-right direction. Therefore, zig-zag phenomenon can lead to inefficient parameter updates during training.
Tanh
ReLU and Its Variants
From the computation graph of neural network, we can see that the path from the loss to a parameter (such as \(w^{L-1}_{12}\) in the example) includes the \(z\) to the parameter \(\frac{\partial z_2^{L}}{\partial w^{L-1}_{12}}\) at last. This term is the activation value, in this example \(a_1^{L-1}\). That is, the gradient of a parameter is proportional to the activation value of the neuron in the previous layer.
ReLU function maps all negative inputs to zero. This means that the gradients of all parameters connected to this neuron will be multiplied by zero during backpropagation, resulting in zero gradients. The derivative of the ReLU activation function is also zero for negative inputs. This is multiplied in the chain rule as well, thus also results in zero gradients. Consequently, these parameters will not be updated during training.
Statistically, there is a 50% chance for a ReLU neuron to be “dead” (i.e., its input is negative) for any given input. It means that, on average, half of the parameters cannot be updated in each training step. This can affect the efficiency of training.
This is even a risk that some neurons may never be activated during the entire training process, leading to a portion of the network being undertrained or not trained at all.
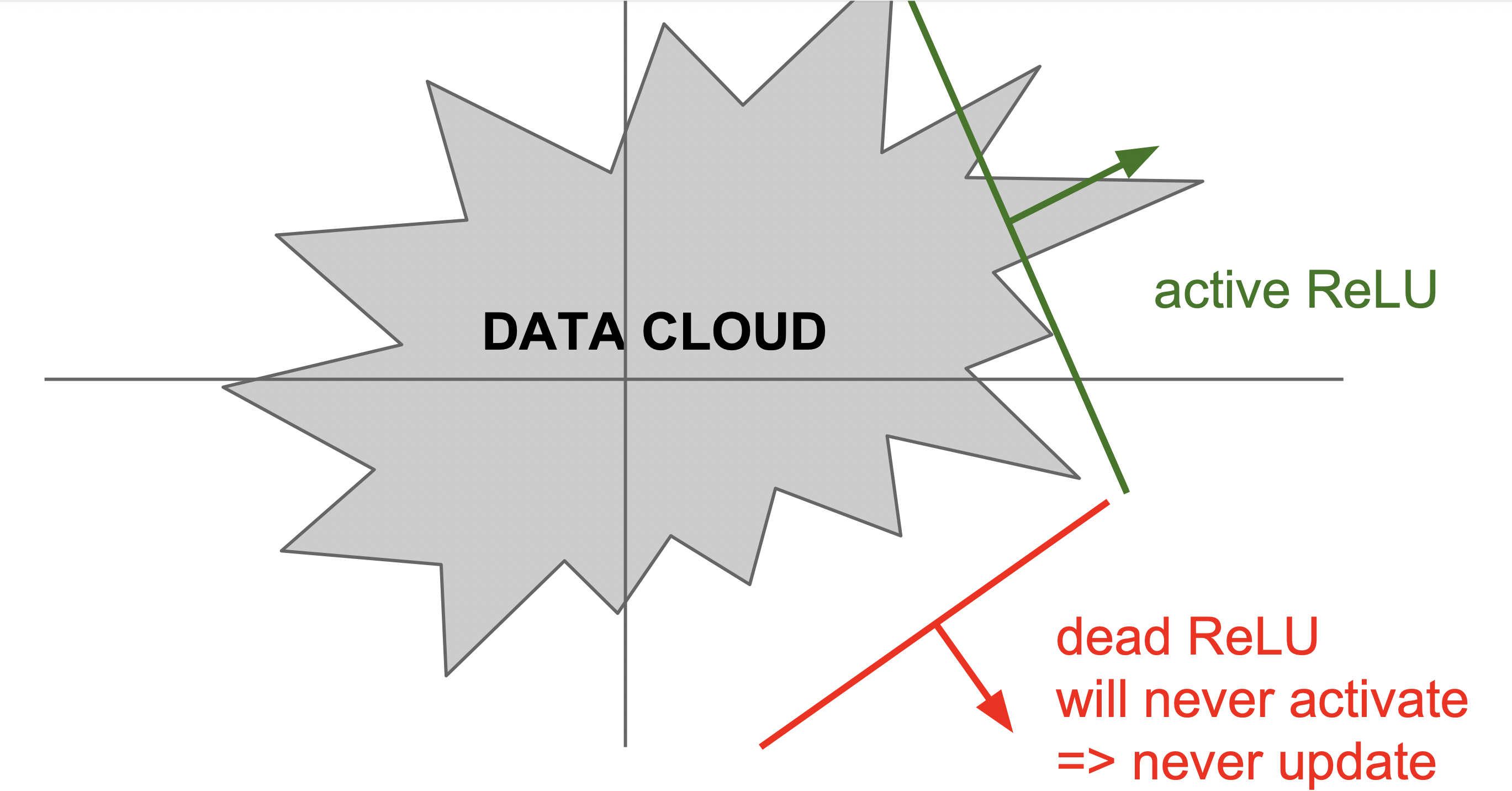
We assume a ReLU neuron receives two inputs from the previous layer, with weights \(w_1\), \(w_2\) and bias \(b\). The neuron is activated if the weighted sum of inputs is greater than 0, i.e., \(a_j^l = w_1 o_1^{l-1} + w_2 o_2^{l-1} > 0\). The boundary condition for activation is \(w_1 o_1^{l-1} + w_2 o_2^{l-1} = 0\), which is a straight line in the 2D space of \((o_1^{l-1}, o_2^{l-1})\). We illustrute this in the figure above. The training data passed in the layer forms a data cloud. A complete dead ReLU neuron happens when the data cloud is entirely on one side of the line. No training data can activate the neuron, so the parameters \(w_1\), \(w_2\), \(b\) will never be updated, making the line fixed.
A bad and unstable optimizer (for example, an optimizer with a huge learning rate) may produce such weights and bias, making the neuron completely dead.
Please note, the data cloud in a layer is the representation of the original input data, not the original input data itself. Therefore, it is not fixed and can change during training, so there is still a chance for the neuron to be re-activated in the future. For further analysis, please refer to (Lu et al. 2019).