My takeaway series follow a Q&A format to explain AI concepts at three levels:
Backpropagation computes the gradients of the loss, where the loss is a composite function of the parameters (composed by the loss function \(l\) and the neural network model \(f\), where \(f\) is a big multivariable composite function of the parameters). In calculus, the derivative of a composite function can be computed by the chain rule. Therefore, the backpropagation algorithm is just an application of the chain rule.
The chain rule for a multivariable composite function is as follows. It is basically summing the derivatives along all the paths from the dependent variable to the independent variable.
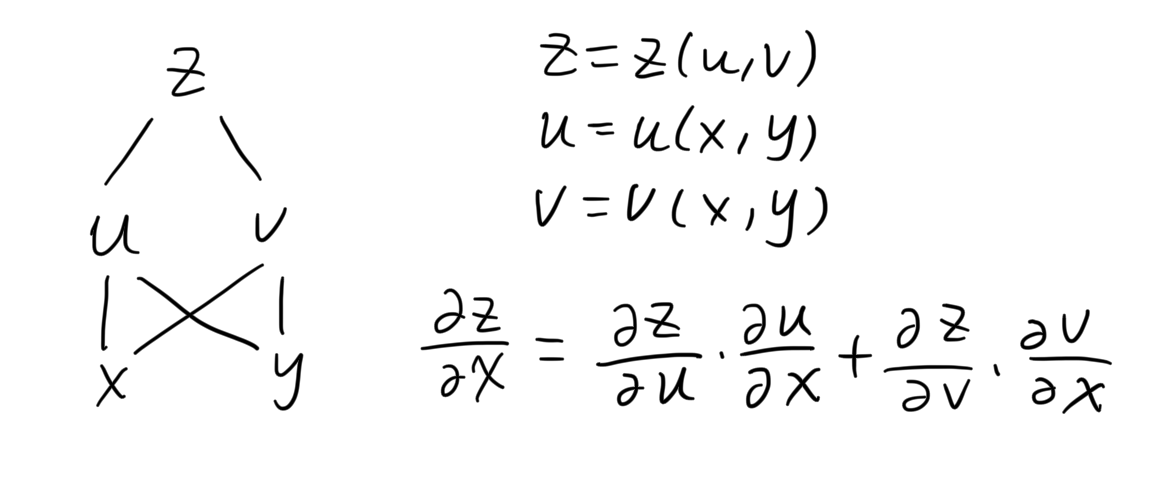
The composition relation between the variables in the function can be illustrated as above, which is called computation graph. For the loss function in neural network training (suppose a feed-forward network for regression problem), the computation graph is as follows:
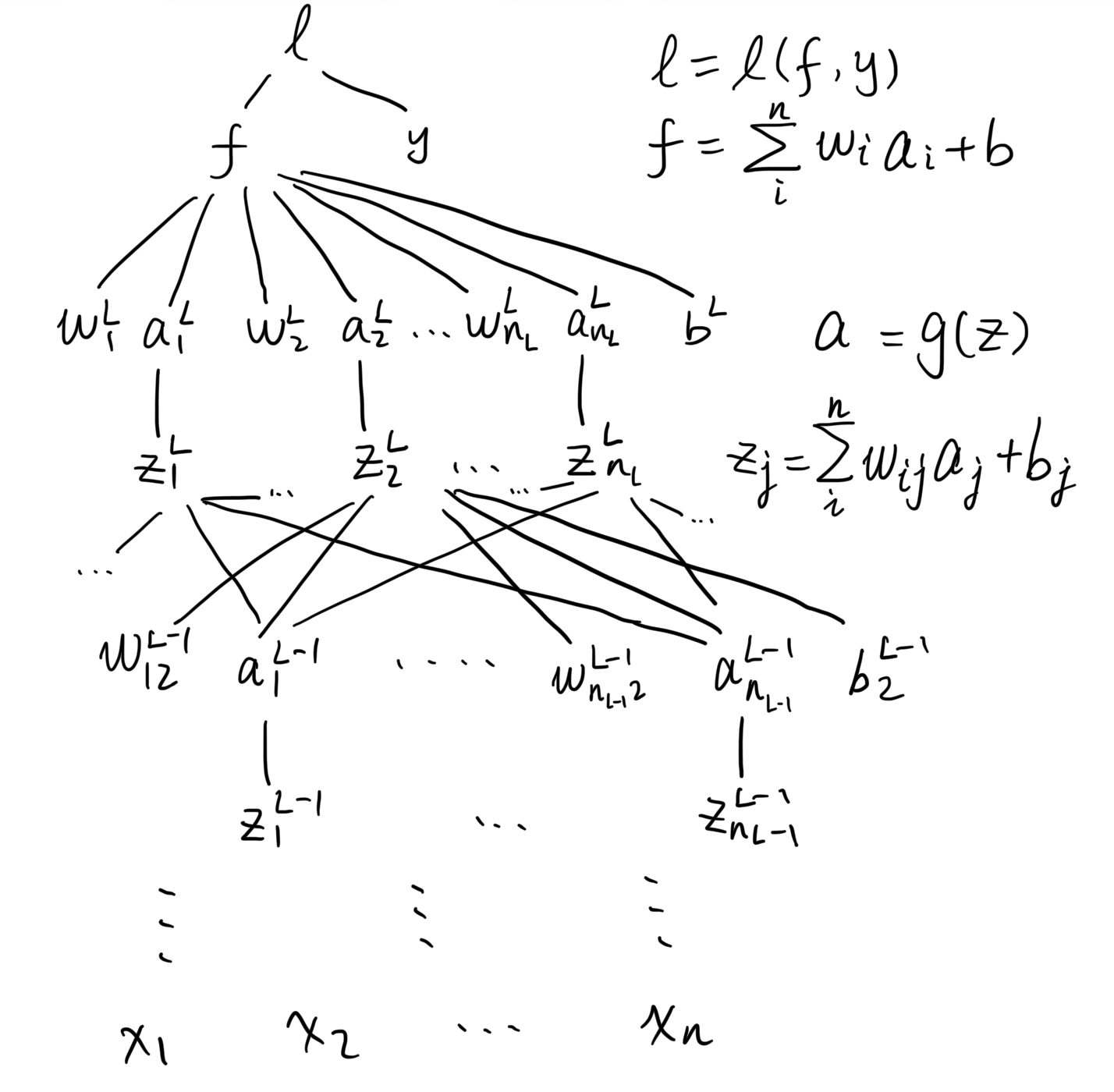
All \(w\)s and \(b\)s belong to the model parameters \(\theta\), so the target gradient to compute are \(\frac{\partial l}{\partial w}\) and \(\frac{\partial l}{\partial b}\). To compute them, taking \(\frac{\partial l}{\partial w_{12}^{l-1}}\) as an example, there is one path only for \(l\) to \(w_{12}^{l-1}\):
\[\begin{align} l &= l(f,y) =\frac12 (f-y)^2\\ f &= \sum_i^{n_L}w^{l}_ia^{l}_i+b^{l} \\ a^{l}_2 &= g(z^{l}_2) \\ z^{l}_2 &= \sum_i^{n_{L-1}}w^{l-1}_{i2} a^{l-1}_i + b_2^{l-1} \\ \end{align}\]
According to chain rule,
\[\begin{align} \frac{\partial l}{\partial w_{12}^{l-1}} &= \frac{\partial l}{\partial f} \cdot \frac{\partial f}{\partial a^{l}_2} \cdot \frac{\partial a^{l}_2}{\partial z^{l}_2} \cdot \frac{\partial z^{l}_2}{\partial w_{12}^{l-1}}\\ &= 2(f-y) \cdot w^{l}_2 \cdot g'(z^{l}_2) \cdot a^{l-1}_1\\ \end{align}\]