这是我在读博期间重新学习 Python 时的一些笔记,经我重新整理成的完整的教程。
我本科作为专业课学习的是 C 语言,Python 作为更方便实现数据分析、AI等的编程语言,是我在高年级阶段后来自学的。当时学 Python 的时候不成体系,不够扎实,主打会用就行,于是在读博进入研究阶段前重新系统地学习了一遍,将自己不熟悉或理解不到位的部分补齐。
请注意,此教程的风格比较抽象、总结,不举生动的例子,旨在把概念言简意赅地说明白,定义清楚,不适合入门;章节按主题组织,只包含难点或不易掌握的点,不能面面俱到,不适合从头开始顺序学习,更适合当作手册。涉及的范围也仅限 Python 语言本身,不涉及第三方库(见我的其他文章,如 PyTorch 学习笔记系列),也不介绍安装、配置环境、IDE 界面等(见我的其他文章,如这篇)。
1 运行方式与基础规则
1.1 运行 Python 程序
Python 程序就是一个扩展名为 .py 的文本文件,里面存放的是 Python 语法的代码。各种 IDE 都有图形界面可以运行 Python 程序,例如通常有一个“运行”按钮。无论是什么形式,所有运行 Python 程序的方式本质上都是执行了命令行中的如下命令(如果不了解命令行,请见我的 Linux 学习笔记):
??/??/python ??/??/prog.py前者指定了 Python 解释器,后者是要运行的 Python 程序。解释器本身就是一个程序,它可以作为命令直接执行,而要运行的 Python 程序相当于这个命令的参数。注意,在一台机器上可能安装了多个版本的 Python,所以要指定具体的解释器路径。
一般 Python 在安装时会被加入到环境变量,所以通常我们可以直接使用如下命令,其中的 python 就等于放在环境变量里的解释器的路径:
python ??/??/prog.py可以通过which python命令查看解释器的路径。
解释器的类型
解释器除了安装 Python 时自带的(称为 CPython,因为底层是用 C 语言开发的),还有很多其他功能更高级的,如 IPython、Python、PyPy、IronPython 等。
IPython 是比较值得了解的,因为是 Jupyter 公司开发的,Jupyter Notebook 用的就是自家的解释器 IPython。可以通过提示符来区分:CPython 的提示符是 >>>,IPython 的提示符是 In [序号]:。
IPython 特色功能是 Tab 自动补全命令、历史记录等,还额外扩展了一些 Python 语法:
!{shell命令}:可以通过 Python 执行 shell 命令;{变量}?:查看变量的相关信息;{函数}?,{函数}??:查看函数的文档、源代码;_{序号},_i{序号}:查看第{序号}次输出结果、语句内容;- 魔法函数是 IPython 预定义的一些命令,以
%开头,例如:%lsmagic:打印可用的魔法函数列表;%time:测试一句代码(跟在它后面)运行时间;%matplotlib inline:要求 Matplotlib 绘图模式是内嵌(inline)模式,即将绘图直接显示在当前命令行中而不是单独的窗口。
在命令行传参
Python 可以在解释器的执行命令中向程序里传参,在一些场景下非常方便。解释器允许传入无限个参数,以空格隔开:
??/??/python ??/??/prog.py arg1 arg2 ...传入的参数交给 Python 程序内部的代码来接收、解析。最简单的解析方式是用sys.argv 来接收(需要 import sys 模块)。它是一个字符串列表,存放了解释器的执行命令的所有参数。以上为例,sys.argv 的内容为 ['??/??/prog.py','arg1','arg2',...]。更高级的解析方式请见我的文章 Python 命令行解析参数。
1.2 变量命名规范
编程语言一般有一些约定俗成的习惯,如变量命名规范,下面是 Python 的:
- 模块名、包名、文件名:单词全小写,加下划线;
- 类名:单词首字母大写,不分隔(驼峰命名法);
- 变量名:
- 普通变量(包括实例):单词全小写,加下划线;
- 全局变量(当作常量):单词全大写,加下划线;
- 函数名/方法名:单词全小写,加下划线。
除此之外,还有一些其他 Python 规定的有实际命名法,用以表示特殊含义(如私有、保护、特殊变量或方法),见 小节 5、小节 6。
2 基本数据类型与数据结构
以下是我整理的 Python 的内置类型(包括了各种基本数据类型与数据结构),它们是逻辑上基本的类型,还有一些零散的内置类型是为其他功能服务的,虽然也是内置类型,但不方便划归到主要的分类逻辑,将在后面穿插讲解。详情请见官方文档。
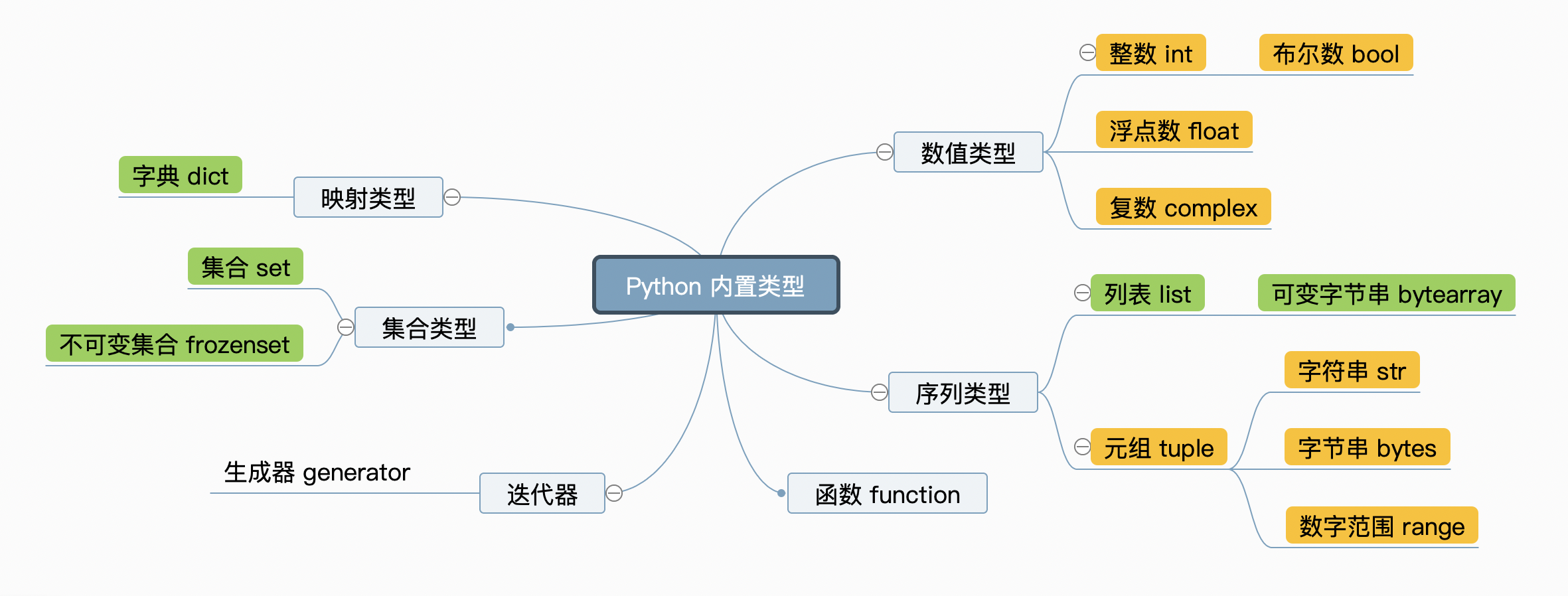
应当强调一件事情:Python 中任何数据类型都是类,任何变量都是对象(类的实例)。Python 定义了一个基类 object,所有内置类型都是它的子类。这是在 Python 安装目录中的源码 .py 文件中定义好的。
Python 是动态语言,数据结构非常灵活。在上图被称为序列类型的容器中,里面的元素可以是任何数据类型。例如列表里的元素可以是列表,从而形成列表的嵌套。
C 语言里经常学的隐式转换在 Python 也有,规则麻烦,没有必要仔细了解,还是老老实实地统一数据类型按规矩来吧,必要时用强制类型转换。强制类型转换函数就是 类型名(),它们是 Python 的内置函数。
除此之外,Python 还有个空类型,用 None 表示。
在上面的列表中,类型间的层级关系表示相应类的继承关系,也就意味着子类继承了父类的操作,又自己定义了一些操作。明白这种关系很有必要,也方便分类记忆操作。
另外,Python 变量类型分可变(mutable)和不可变(immutable),前者可以修改数据结构里面的值,后者只能看作一个整体。在上图中,红色是不可变类型:数值类型、元组、字符串等,蓝色是可变类型:列表、字典、集合等。这个概念非常重要,是理解 Python 变量机制的关键。
2.1 Python 变量赋值机制
在介绍具体数据类型前,先强调 Python 变量的赋值机制,对下文深入理解非常重要。先说结论:Python 所有变量都是一段内存空间的标签,或称引用。
以一个简单的赋值语句为例:A = B,深究它其实有很多东西。先看 C 语言:
- 设 B 是常量,第一次对 A 赋值是初始化,系统为 A 分配一块内存空间存放 B;
- A 和这一块存储空间是绑定死的,之后的赋值都是修改这块空间;
- 设 B 是变量,赋值操作也是把 B 的内容取出来,复制到 A 的这块空间。注:C 语言不存在大小不合适放不进来的问题,因为 A、B 的类型都声明过了,如果不同会报错(不考虑强制类型转换)。
再看 Python 语言:
- 设 B 是常量,第一次对 A 赋值是初始化,和 C 语言一样,系统为 A 分配一块内存空间存放 B;
- 但 A 不是绑死在这块空间的,之后遇到新的赋值
A = B'(B’ 不等于 B) 时,会为 B’ 分配一块新的空间,然后将 A 绑定到这块空间; - 设 B 是变量,赋值操作是将 A 绑定到 B 绑定的那块空间。
Python 内置函数id() 可以查看变量,与 C 语言 取地址 & 运算符类似,以上内容可以用此函数验证。
这种灵活的绑定与换绑就是“标签”的逻辑。可以把常量想象成客观存在的物体,如桌子、凳子、电脑;变量就是一堆贴纸,赋值操作就是拿着贴纸贴来贴去。
标签机制也解释了为什么 Python 语言是动态的,即一个变量不需要声明其类型,是在被赋值后才确定类型的。因为它就是个标签啊!
因此,Python 中的 del 语句仅仅是删除了变量与数据的绑定,而不是真正释放了内存。Python 是高级语言,垃圾自动回收,不需要显式地销毁对象。
可变类型内部机制
这里要涉及一下可变类型与不可变类型的区别。它们都是变量,如果把变量看作整体的话,上面的“标签”机制都是适用的。但可变类型还可以修改里面的值,例如考虑列表修改元素 A[i] = B,这时“标签”机制还适用吗?
可变类型就是一撮不可变类型和可变类型的集合,如此递归下去,即可变类型就是一撮不可变类型的集合。它存放里面的每个不可变类型都是以变量的形式,所以就是一个盛放标签的容器。这个机制对区分可变与不可变至关重要,也对理解 Python 函数传参方式至关重要。
以列表和元组的区别举例,A1 = (1,2,3,4,5) 和 A2 = [1,2,3,4,5] 的区别在于,前者是不可分割的一个整体,后者相当于一个盛了 5 个变量 a,b,c,d,e 的桶,它们分别是贴在整数 1,2,3,4,5 上的标签。因此,对上面问题的回答是肯定的,比如 A2[0] = 0 就是把贴在 1 身上的标签 a 撕下来贴到 0 身上。
Python 复制可变变量的坑
方便性自然会带来一些麻烦。Python 这种灵活的变量赋值机制也会带来麻烦,例如这里要介绍的是在复制可变变量时的坑。这也是为什么要了解这些机制的原因,因为如果还按照 C 语言的理解方式的话,写代码时可能会遇到不了解就永远想不通的 bug!
以列表为例,假设想把变量 B(是个列表)复制一份给变量 A,并要求这两份完全独立。可以想到很多方式:
A = B:这个在 C 语言都知道是错的,不过原因是 A、B 是数组的第一个元素地址。 Python 中如果这样的话,会把 A 这个标签贴到 B 贴的地方,之后它俩是联动的,一个动另一个也跟着动,因为指向的是一个东西;A = B[:]或copy()方法:切片切全部。这个语句原理是:虽然 B 是变量名,但是B[:]就是具体的一个列表了。但是问题在于,如果列表里面的元素有可变类型的话,复制这个元素就属于第一种A = B的方式了。copy()方法等同于A = B[:];- 写循环语句,按元素复制:这个可以确保没问题,但是比较麻烦。我之前碰到 bug 后就直接这样做了,有点笨;
A = copy.deepcopy(B):这是一个终极杀招。调用copy库中的deepcopy()函数,会递归地(深度优先)复制列表的每一个角落。
上面第 2 种方法称为浅复制(顾名思义就是只复制了列表的最外面一层),第 4 种方法称为深复制。可以看到,Python 中这些复制的区别就是列表变量的“标签”机制引入的麻烦。
以下小节介绍 Python 各类型,分成几组来讲。
2.2 数值类型
编程语言的基本数值类型,逻辑上就是整数、浮点数、复数。Python 只有这三个数值类型,不像 C 语言那样还要区分整数的位、符号、浮点数的精度等(例如:long、int32、float64),也不用考虑溢出等问题,按照其逻辑意义放心使用就行,非常省心。
数值类型的操作一般通过运算符来定义。常用的运算包括:
- 四则运算:加、减、乘、除、余数、幂……
- 比较运算:大于、小于、不等于……
- 布尔数:与、或、非……
- 整数的按位运算
- 复数:取实部、虚部、共轭……
- 增强赋值:二元运算符 +
=
这些运算都是学编程或数学时最基础的知识,不再赘述。不同编程语言可能在符号上有所不同,现查就可以了,不用专门去记。
2.3 序列类型
序列类型包括基本的列表和元组,还有一些数据类型是它们的子类:
- 字符串(string):只能存字符的元组;
- 数字范围(range):只能存等差整数列的元组,一般用于 for 循环;
- 字节串(bytes):只能存 ASCII 字符的元组;
- 可变字节串(bytearray):只能存 ASCII 字符的列表。
列表/元组,才是这些数据类型的本质。它们并不是单独的、全新的类型。这样也就解释了诸如为什么字符串操作和元组类似的问题,因为字符串就是个元组。
非数值类型(包括序列类型和下面的集合、字典等)的操作通常由 Python 内置函数或该类的方法定义,也有些常用操作会重载符号。
可变和不可变类型共有的操作是一些访问操作,例如切片、取最值、拼接(注意拼接这类操作会返回新的对象而不是原地操作);可变类型特有的是修改操作,例如添加、删除、替换。
2.4 集合与字典
我把集合和字典放在一起说,因为它们都模拟了数学概念(集合、映射)。这些数学概念本身就是从现实世界中抽象出来的,所以对应的数据结构在编程中也很实用。
集合可以理解成是操作受限的线性表,而且是无序的。受限的操作就是集合的交、并、补等运算。另外,集合也分可变(set)和不可变(frozenset),是两种不同的数据类型。
字典其实就是数学上的映射(或称函数),但定义域是有限的集合。字典是无序的,因为映射的概念也没有给定义域赋序。有序字典 OrderedDict 需要使用额外的 Python 库 collections。对字典的操作与数学上对映射的操作对应,例如可以取定义域、值域等。
字典是一种高级数据结构,它可以立刻按照键查找对应的值(\(O(1)\))。计算机的物理存储是不支持这样高级的操作的,因为各级存储都是数组:值按顺序存放,只有按照位置序号访问值才是 \(O(1)\) 的。字典一定是把数组包裹了一层机制才能做到按键查找 \(O(1)\) 的。在 Python 中,字典的底层实现是哈希表。对于哈希算法,在存元素的时候,就不按顺序存放,而是通过哈希函数计算出一个索引,然后存到数组中索引的位置。这样在查找时,通过哈希函数获得索引是 \(O(1)\) 的,取数组索引位置的操作是 \(O(1)\) 的,所以最后整个操作也是 \(O(1)\) 的。详情请见我的这篇介绍哈希算法的文章。
2.5 迭代器与生成器
这部分是高阶内容,需要花较大篇幅讲解。
概念理解
迭代器是一个用于遍历,并能记住遍历位置的类。可以将其看作一个售货机,一开始里面装满了商品,每次投币它就会吐一个商品,吐完了机器就会报错(也可以设计永远吐不完的迭代器)。迭代器每次投币后会吐什么东西,什么时候吐完,都是代码自己定义的。
大家可能会问,之前介绍的序列类型不是已经实现这种功能了吗:循环列表中的元素也能实现这个功能。其实,Python 的序列类型可以直接构造迭代器,但还有很多其他的方式,见小节 2.5.3。 其他方式设计的迭代器有很多额外的优点:如不需要事先计算并存放好所有要遍历的元素(例:深度学习把一批批数据放在叫 Dataloader 的迭代器中),有的可以实现无限遍历下去(例:自然数),等等。
应当注意,迭代器是一次性的,实例创建了之后,就开始计投币,无法撤销。因为迭代器就是用来遍历的,别无他用,吐完了的迭代器就废了没用了,没法重置。因为这种一次性的特性,Python 设计者干脆设计了一种工厂,专门生产(即创建实例)这些一次性的迭代器,用完了没关系再生产一个就得了。这个工厂就是所谓的可迭代类。
用法
当一个对象 A 属于可迭代类(严格定义见下一小节)时,调用 iter(A) 返回一个迭代器对象(相当于工厂生产了一个一次性的迭代器)。设它为 I,每调用一次 next(I),就相当于投一次币,吐出来的商品就是 next() 函数的返回值。多次调用 next(I) 后,有限的迭代器最终会吐完抛出异常 StopIteration,无限的迭代器可能永远不会。这些表现都由迭代器的设计者定义。
一种简便的方式实现上述 next() 的操作是 for 循环。实际上,for 循环代码:
for x in A:
... 在 Python 中等价于:
I = iter(A)
while True:
try:
x = next(A)
...
except StopIteration:
break这样就不用多次手动调用 next() 函数,还能自动检查是否碰到了 StopIteration(即是否吐完),防止程序报错。
上面的等价代码就是 Python 中 for 循环的本质,它只是用 while 循环定义的一种简便写法,并不是一种新的循环语句。For 循环语句中的 in 后面必须是可迭代类型。
Python 内置函数 zip() 可以将多个可迭代类的对象打包在一起,构成一个以元组为元素的可迭代对象。此函数常用于 for 循环中有多个变量同时循环:
for x, y in zip(A, B):
...A、B 长度不一致时,取最短者。
定义迭代器
定义迭代器有两种方式,可以从头自定义,也可以从内置类型构造。注意,理解下面的内容需要理解 Python 的类与继承,见小节 5。
从头自定义
Python 在类中提供了两个特殊方法:__iter__() 和 __next__() 。这两个方法定义了 Python 的内置函数 iter(),next() 作用在此类实例上的效果。这两个方法有特殊要求:
- 只能有一个参数
self; iter()只能返回Iterator对象。
一般是:
__iter__()定义一些实例属性,用于存放基础数据,通常返回self自己;__next__()定义向下迭代的规则。
以数列为例,会在前者存放初值,后者存放递推公式:
class Fibonacci:
def __init__(self, n):
self.n = n # 控制生成多少项
self.count = 0 # 当前已生成的项数
self.a, self.b = 0, 1 # 初始两个数
def __iter__(self):
# 返回迭代器对象本身
return self
def __next__(self):
if self.count >= self.n:
raise StopIteration # 迭代结束
# 取当前值并更新状态
value = self.a
self.a, self.b = self.b, self.a + self.b
self.count += 1
return value
# 使用迭代器
fib = Fibonacci(10) # 生成前 10 个斐波那契数
for num in fib:
print(num, end=" ")Python 根据方法的定义情况自动判断:
- 如果
__iter__(),__next__()都定义了,是Iterator类; - 只定义了
__iter__()的是Iterable类,即可迭代类。
任意一个类(不需要显式继承 Iterator),只要把这两个方法定义了(称实现迭代器),它就是可以像上小节的 A 那样用了。
按照这个定义,__iter__() 返回 self 自己没有问题,因为 self 定义好了两个方法,本身就是 Iterator 类。
从内置类型构造
Python 本身的多数能当数据“容器”的类型,包括:列表(list)、元组(tuple)、字典(dict)、集合(set)、字符串(str),已经定义好了 __iter__(),但没有定义 __next__(),所以是可迭代类。其中 __iter__() 都不是返回自己,而是一个新的类的对象,如列表的 __iter__() 返回 list_iterator 类(这个类定义了 __iter__() 和 __next__(),是 Iterator 类)。
所以这些 Python 内置类型直接用 iter() 包裹一下就是个能用的迭代器,其迭代方式自然地是依次访问容器里的第 1, 2, … 个元素。
这里只是讨论这些内置类型的原理而已。平时使用中,根本不会涉及迭代器这个概念,因为对其的遍历、迭代通常是 for 循环,连 iter() 函数都不会出现。
生成器
Python 另外提供简捷的语法实现迭代器。以下两种方式叫生成器(generator),它是 Iterator 的子类。这个类没有什么特殊的,暂时理解为普通的迭代器即可。语法如下:
- 将函数的
return改为yield,函数就变成了生成器。这种生成器函数会 yield 很多次(通常把 yield 语句包在循环中),其迭代方式就是依次访问第 1, 2, … yield 出的东西。例如,上述数列可以用生成器写成:
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a # 每次返回一个值,但不会退出函数
a, b = b, a + b
# 使用生成器
for num in fibonacci(10):
print(num, end=" ")- 有一种快速构造列表的语法,形式如
[f(i) for i in A]。如果把外面的中括号换成小括号,就是构造生成器(并不是元组),这种方式有人称为列表生成式。这里不详细讨论。
其他 Python 预定义的数据结构
- 枚举(enum):与 C 语言中的枚举类似(Python 3.4 版本新功能);
- 文件(file):在 Python 中文件也是类,打开的文件都会创建一个 file 类的实例。此类定义的主要操作有打开、关闭、读取、写入等等。
Python 标准库 collections 中有其他更高级的数据结构,例如双向列表、有序字典、计数器等等。有需要可查看官方文档。
3 控制流
与一般的编程语言相同,Python 共有三种控制流:顺序、条件、循环。其中各有一些我不太熟悉的用法,列举如下:
- 空语句
pass,什么也不干。某些时候为了保持程序结构的完整性,必须填一个语句,用pass来占位; - del 语句:可以
- 删除变量与数据的绑定;
- 删除容器类型中的元素;
- 条件多选择:在 C 语言中有 switch 语句,但 Python 只能用
if...elif...else实现。(Python 3.10 新引入了类似 switch 语句的 match 语句,但应慎用); - 循环语句后加
else:这是个语法糖,在循环正常执行完毕(指没有通过 break 跳出)后会自动跳到 else 语句,适用于检验是否循环被 break。这个也可以用在循环中加 flag 来实现。
4 函数
我之前只是知道最基本的函数定义,并知道 Python 是动态语言:函数非常灵活,不需要规定参数和返回值的类型。本节系统介绍 Python 的函数,还是有很多知识可以学的。
函数语法如下:
def 函数名称(参数列表):
'''
文档字符串
'''
return 变量函数开头三个引号的注释能当作函数的文档,和文档系统更集成,例如可以通过一些命令查询显示出来,而 # 开头的注释起不到这个作用。
4.1 变量的命名空间与作用域
Python 变量的命名空间与作用域和 C 语言是差不多的(暂不考虑下文中函数中嵌套函数的情况):
- 内置变量:Python 自带的变量;
- 全局变量:在函数外定义,对当前文件(模块)生效;
- 局部变量:在函数内定义,只对此函数生效。
Python 中没有定义外部变量的机制。外部变量的实现方法是,用一个配置文件(模块)统一定义各种常量,在要用到的文件中 import 该模块。
Python 的命名空间规则(和 C 语言一样)类似文件系统命名规则,全局变量和局部变量可以重名。如果想在函数内使用重名的全局变量,应使用声明语句:global 变量名 或 nonlocal 变量名。
4.2 参数传递方式
先复习一下 C 语言。C 语言中函数有两种参数传递方式,搞不清楚这两种方式,就容易出现写函数时不小心把实参修改了这种情况:
- 值传递:相当于在函数内定义里一个局部变量(形参),初始化为传进来的(实参)值,形参动实参不跟着动;
- 引用传递:形参是实参的引用,形参动实参跟着动。
C 语言是通过在函数定义处参数前加上特殊符号来区分的。例如加 *, & 可实现引用传递,不加就是值传递。数组都是引用传递。
在 Python 中,参数传递规则理解起来很简单:传进来参数后,它做的事情就相当于在函数开头加了句 形参 = 实参。
那么它是什么类型的传参方式呢?实际上是都有。严格意义上,我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
现在考虑一个问题:在 Python 中形参动了,实参会不会跟着动?根据 Python 变量的赋值规则(“标签”机制),如果是整体地动形参,则只是换绑了形参的标签,不会影响实参,此时为值传递;如果形参是修改可变类型的内部,则只是把里面变量换绑了,而形参作为可变类型包含的变量没有变,此时为引用传递。
也就是说,Python 的参数传递规则是根据变量是否为可变类型自动决定的。如果想自己决定怎么办?把变量类型改一改即可,比如把整数用中括号包裹后再传进去,值传递就变成了引用传递。
4.3 参数列表
Python 函数的参数列表最多可以有 5 部分组成:位置参数、默认参数、可变参数、命名关键字参数、关键字参数。规定:
- 每一部分都是可有可无;
- 参数列表必须按照这个顺序写,否则会报语法错误。
传参有两种写法:一种前面带 参数名=,另一种不带直接传。
def func(arg, default_arg=0, *args, arg2, **kw):以这个 5 部分都包含的函数为例,这 5 个参数分别是:
- 位置参数:放在最前面,以位置来标识参数;
- 默认参数:带了默认值的参数;
- 可变参数:可以包含多个元素,只能写一个;
- 命名关键字参数:必须以前面带
参数名=的形式传的参数,如上例必须以arg2=值的形式传入; - 关键字参数:同上,但参数名不受限制,只能写一个(效果类似可变参数,可以理解为可变的必须带关键字的参数)。
有一点应说明,命名关键字参数(4)和普通的位置参数(1)写法是一样的,如果它们之间的默认参数(2)和可变参数(3)都没有,怎么区分呢?Python 额外规定了语法:中间用*隔开。这个 * 不是参数,只起到分隔符的作用。
函数传参后,Python 解析参数的方式是贪心的、有优先级的,即先处理前面的,把吃剩下的施舍给后面:
- 先按照位置识别位置参数,所有位置参数必须一一传入,否则报错;
- 再识别默认参数,识别到了就传给它该有的值,识别不到就设为默认值;
- 再识别可变参数
*args:- 只考虑剩下的不带
参数名=的(不可以直接传args=或*args=),统一传到args的元组里; - 还能识别前面带
*的实参,此实参必须是元组(列表也行),可以直接传入args元组,只识别一次;
- 只考虑剩下的不带
- 再识别两种关键字参数。此时剩下的一定都是带
参数名=的(如果有不带的会报错):- 先检查前几个和命名关键字参数是否一致,不匹配直接报错;
- 剩下的全部识别为关键字参数
**kw:- 统一传到
kw的字典里(键对应参数名,值对应参数值); - 类似地,也能识别前面带
**的实参,此实参必须是字典,可以直接传入kw,只识别一次。
- 统一传到
如何表示任意函数?因为没有规定参数数量,就要用到两种可变的参数——可变参数、关键字参数:
def func(*args, **kw):args、kw 是习惯名,用别的名字也可以,只要前面加上了 *、**。
4.4 返回值
Python 函数可以有多个返回值,以逗号隔开。return 语句和函数调用里的返回值个数和顺序应一致,否则会报错。
Python 函数返回多个值时,有的我们不需要,可以用 _ 代替,例如:
def func(...):
...
return A, B
_, B = func(...)很多检查语法错误的插件会警告没有使用的变量,但如果变量名为 _, 则不会警告。
4.5 函数也是类
本节涉及很多函数式编程的理念,不会详细讲原理,因为 Python 本身是面向对象编程,只是有一点函数式编程的特性罢了。
函数也是一种类(定义在 Python 安装目录下的某个源码 .py 文件中),也继承自 object 基类,有函数特有的属性与方法,也有通用的如 __name__。所以函数名也是变量,是变量就可以赋值、当作参数传入、返回值返回等等。
注意,C 语言也可以把函数当参数或返回值传入传出,但原理完全不一样。C 语言是通过函数指针实现的,本质上是函数的地址。
匿名函数
匿名函数就是函数的换皮缩写版:设输入为 x,输出为 f(x),则写成 lambda x: f(x)。它与以下函数是等价的:
def 函数名(x):
return f(x)匿名函数这种简写形式可以方便把函数当参数传递,就不用在外面额外定义了。下面要讲的是高阶函数,指输入输出中有函数对象的函数。
Python 标准库 functools 有很多处理高阶函数的工具。本文不打算讲解这些工具,只讲基本概念。
闭包
函数外面再套一层函数把它包裹起来,叫闭包。任给一个函数
def func(*args, **kw):
# ...
return r其闭包为:
def closure_func(*args, **kw):
def func():
# ...
return r
return func将函数写成闭包形式的作用是通过运行闭包 func = closure_func(*args, **kw) 暂时记住函数和它的参数(都打包在了 func 变量里面),但先不运行(一般出于节省计算资源考虑);在要运行的地方直接调用 r = func() 会更方便,不需要传参数。
装饰器
Python 中有在函数前加 @开头的语法:
@dec
def func(*args, **kw):称 dec 是 func 的装饰器。加了装饰器后的 func,在调用之前会先 func = dec(func),再执行调用 func(...):。即先用装饰器用装饰一下原来的函数(这时的 func 已经不再是原来的),再使用 func。
这对装饰器函数 dec 的内容有要求,否则在调用 func 时会报错。至少它的输入输出都必须是函数。至于怎么装饰则是用户定义的了。以下的例子实现了在调用函数 func 前打印 “正在调用 func 函数” 的日志:
def log(func):
def wrapper(*args, **kw):
print("正在调用" + func.__name__ + "函数")
return func(*args, **kw)
return wrapperPython 也有一些内置函数(下文会涉及到),就是专门用来当装饰器的,直接拿来去修饰函数即可。
5 面向对象编程
Python 是面向对象的语言。之前提过,在 Python 中万物皆对象。因此这一部分应该属于最基本、底层的知识。面向对象的基本机制是封装、继承与多态,以下分别介绍。
5.1 封装
形式上,类是一段封装了各种变量和函数的代码块。以下是一个例子:
class Class(object):
'''
文档
'''
A = 1
def __init__(self, B):
self.B = B
def method(self):
C = 2
return self.B类里面出现的变量分为三种:
- 实例属性:类的实例自己的属性,通过
实例.属性调用,例如 B。不可以写在方法外面,定义和调用时总是以实例.属性的形式出现,例如self.B; - 类属性:整个类自身的属性,通过
类.属性调用。例如 A。写在方法外面,和方法并列; - 普通的局部变量:其他写在方法里面的普通变量。例如 C。
类里面的函数叫做方法,分几种:
注意,这里提到“类里面的函数”是不准确的,我想表达的意思是类中用 def 语句定义的长得像函数的代码块。之前强调过,函数也是类(见 小节 4.5),类中有方法,所以是先有了类、方法的概念,才有了函数。
- 实例方法:普通的 def 语句定义出的都是实例方法,它至少有一个参数,第一个参数是实例本身(习惯起名为
self),在调用时省略; - 类方法:用装饰器
@classmethod修饰,至少有一个参数,第一个参数是类本身(习惯起名为cls),在调用时省略; - 静态方法:用装饰器
@staticmethod修饰,只是形式上在类中,与类不绑定,对参数没有限制。
类的属性或方法的名称有时是有实际语法意义的:
__init__():构造方法,在类创建实例时自动执行,一般在这里统一定义实例属性;__名字__:有特殊用途的属性或方法,通常另作他用,去完成一些扩展的功能;有很多是在基类object定义的;__名字:私有(private)属性或方法,外部代码无法直接调用,调用会报错;(注:__名字__不算私有属性或方法)_名字:受保护(protected)属性或方法,提示最好不要调用它,但调用并不会报错。
以下列举了一些特殊属性或方法,它们在基类 object 中定义,所有类都可以使用它们:
- 类的信息:
__name__:类属性,返回类的名称;__class__:实例属性,返回实例所属的类;__dict__:作类属性时,返回所有类属性和方法;作实例属性时,返回所有实例属性;
- 定制类:规定 Python 内置函数在该类上的行为
__len__():规定len()函数;__str__()、__repr__():规定print()函数(优先使用后者);__call__():使该类的实例可以像函数一样被调用(callable),此“函数”与__call__()方法一致;__iter__(),__next__():规定iter(),next()函数(见小节 2.5);__getitem__(),__setitem__(),__delitem__():使该类的实例可以像列表那样用中括号下标取、赋值、删除(del 语句)元素;__getattr__():规定在调用该类没有的属性和方法时的行为;__slots__():规定类允许添加的实例属性;
- 定制运算符:
__add__()、__and__()等带运算符名称的特殊方法,可以使运算符作用在该类的实例时合法,具体行为在这些特殊方法中定义。
5.2 继承与多态
Python 继承与多态的规则如下:
- 继承的语法是把继承的父类名写在类名后的括号里,不写则默认继承基类
object; - 子类会拥有父类的所有属性和方法,可看作把父类定义的所有代码复制了过来;
- 子类不仅是子类,也是父类(即多态);
- 子类可以定义新的属性或方法;
- 方法重写:子类里写与父类名称相同的属性或方法,会覆盖掉;
- 不允许方法重载,即有相同的名称,但是参数列表不相同;(同理也不允许函数重载)
- 允许多重继承,在类名后的括号里以逗号隔开。多重继承使得继承的树形结构变成有向无环图结构。
Python 所有的类都继承自一个共同的基类 object(注意是小写),就像森林的所有的根结点有一个共同的父节点一样。这个基类会定义一些共有的、通用的属性或方法,如上面列举的特殊属性与方法。
从以上介绍的内容看, Python 似乎与其他面向对象的语言(如 C++)没啥区别,都是面向对象的那一套理论的实现。它和 C++ 的主要区别在于 Python 是动态语言,实例的属性和方法都是可以临时添加或删除的,而 C++ 等语言则必须在类定义时声明。
super()函数
考虑一个问题:每个类一般都要写构造方法 __init__() 来定义一些实例属性,但是子类和父类的构造方法是重名的,那岂不是把父类的重写了?想要继承父类__init__() 中定义的实例属性怎么办?
在 Python 中,并不需要手动把代码复制过来,只需在子类中的 __init__() 里调用 super().__init__(...) 即可。(注:... 中是父类方法的参数,不需要带 self)。关于更多 super() 的用法和涉及多继承时的坑,可以看我的这篇文章。
5.3 获取对象信息的内置函数与方法
下面列举与类有关的接口,有的是 Python 的内置函数,有的是类自带的方法:
type(A):返回变量 A 的类型。本质上由于所有变量都是对象,它返回的实际上是对应的类名;isinstance(A, Class):判断对象 A 是不是类 Class 的实例;dir(A):获取对象 A 的所有属性与方法;help(A):查看对象的帮助文档;callable(A):判断 A 是不是可调用对象。
6 Python 模块
在 Python 中,一个 .py 文件就是一个模块。本节介绍模块相关内容。
6.1 模块的组织
组织模块最简单的方式就是在一个目录下写很多并列的 .py 文件,这样就有了很多模块。但很多时候,模块间有逻辑上的层次关系。由于模块就是文件,所以可以用文件系统的层级关系(即文件夹)实现,但必须手动规定,Python 不会把所有的子文件夹视作自己人。手动规定的方式是在目录中添加 __init__.py。Python 只识别有 __init__.py 文件的文件夹中的模块。注意这和文件系统还不太一样,文件系统是分文件(叶子结点)和文件夹(内部结点)的,文件夹只起到组织结构的作用,没有内容。而 Python 模块的内部结点是有内容的,写在 __init__.py 这个文件里。所以,__init__.py 也是个模块。
模块的层级关系表示方法也是以点表示:父模块名.子模块名。到了叶子结点后,再往下的点表示的就是模块里的变量、类或函数了。像这样的一整套多层的模块通常称为包(package)。Python 内置的标准库以及 pip 安装的第三方库就是包的形式。例如下图是 PyTorch 包结构:
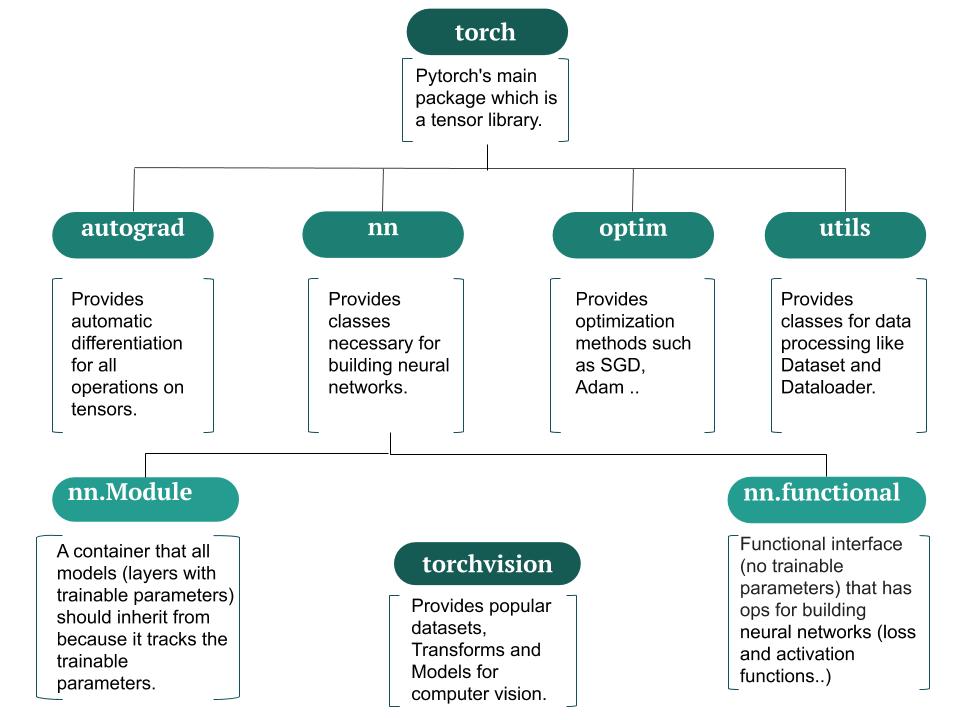
想要把自己的代码做成开源工具,最好是打包成包。所以在写模块时,最好在源代码的各级目录中都添加好 __init__.py 文件,使其构成包。
6.2 模块的使用
使用模块主要是通过各种含 import 关键字的语句。
这里会有一个疑问,模块不就是 .py 文件吗,直接运行不就得了?例如要运行模块 A,A 依赖模块 B,可不可以不在 A 的代码中 import B,而是先运行 B 再运行 A 呢?
一个原因是在终端里执行完一个 .py 文件,程序就真正结束了,内存得到释放(VSCode 运行 Python 代码也是在内置的终端里跑的)。而有些环境配备了更强大的功能,例如:
- Spyder:每跑完一个 py 文件后,它的工作区会记录下此程序的所有变量,相当于跑完程序没有去释放内存。释放内存需要手动去 clear 工作区。
- Jupyter Notebook:直接把一个个代码块(严格来说不是模块,因为一整个 ipynb 格式的笔记本才是一个文件)当作进入 IPython 提示符后执行的一块块表达式,虽然逻辑不太一样,但也有起到那样的效果。
即使可以用这些环境解决这个问题,还有很多不方便:
- 有很多模块时,并不想去跑去逐个运行一遍,只想运行一下主程序;
- 标准库、第三方库都放在隐藏位置,找出来也很麻烦。
但这些都不是本质的。最重要的事情是:模块也是一种封装机制,它把各种函数、类和变量采用类似于 class 的方式封装起来(调用时前加 模块名. 以区分),而不是把各种变量混在一起,只当作按照不同顺序执行的代码块。这体现在各种 import 语句的效果上,见下:
import package:模块当作一个更大的大“类”被定义出来,调用模块中的类或函数也和类差不多,都是加点:模块名.类或函数名。注意:- 可以一次 import 多个,以逗号隔开;
- 可以为模块取别名,在后面加
as 别名;
from package import ...:若package是内部结点模块,可 import 子模块;若是叶子结点模块,则可 import 模块里的变量、类或函数。from package import *可以 importpackage这一级的所有内容。
实际上,from package import * 就起到了“直接运行”的效果。但实际上这个语句并不常用,可见平时大家都是在利用模块的封装功能的。
在使用时,Python 的寻找顺序为:先从当前目录下找,再去 Python 的安装目录里找,都找不到的话就报错 ModuleError。
__init__.py 除了是识别模块结构的占位符外,在语法上也有作用。为什么这个模块叫 __init__.py?因为 Python 规定,在用 import 语句调用各级模块时,涉及到的各级 __init__.py 也会自动调用。这就可以理解为模块的构造方法。
6.3 模块文件模版
一个标准的模块的模版如下:
#!/usr/bin/env python3
# -*- coding: encoding -*-
' 文档 '
__author__ = '作者名字'
import ...
def ...:
class ...:
if __name__ == '__main__':
...标准注释
最开始几行的格式化的注释是标准注释,并不是单纯的文本,解释器其实是可以识别注释中的某些格式、提取出一些配置信息的。
第一行由 # 和 ! 组合的叫 Shebang(或 Hashbang),是类 Unix 操作系统的特有的东西。在代码文件中出现这一行,操作系统会将 #! 后的东西作为解释器来执行。这一行平时是不加的,因为通常解释器都由 IDE 或 Conda 环境指定好了。
代码的字符编码也用格式化的注释定义,见例子的第二行。encoding 是编码标准,如 utf-8,cp1252 等。如果不加这行注释,则表示默认为 utf-8。请注意,Python 作为文本文件,它自己本身是定义过编码的(例:Windows 记事本在保存文件时有选择编码的选项),这是文件本身的属性,定义在整个文件的前 2 个字节。上面注释的定义并不是指这个编码,它规定的是 Python 解释器如何读取解析这个代码文件,通常对输入输出中的符号起作用。我不打算仔细研究这些东西,直接上懒人包:怕遇到乱码就直接 utf-8,把文本文件和第一行注释都设置好,应该就不会出问题了。
模块的文档
Python 模块视第一个字符串为模块的文档,类似于函数的文档。注意它不是写在注释里的,而是字符串。
作者信息由特殊变量 __author__ 字符串定义。
类与函数定义区
正文开始一般会定义一些类或函数。在模块中的变量、函数也可以加下划线表示特殊语法意义,和类是一样的道理:
__名__:模块特殊的变量、函数、类;__名:表示模块私有(private)的,模块外无法直接调用,调用会报错;_名字:表示模块受保护(protected)的,提示最好不要调用它,但调用不会报错。
主程序运行区
定义完类与函数后,就是运行程序的主要代码。这部分代码通常由 if __name__ == '__main__': 包裹。__name__是模块。只需知道加上这行起到的效果:
- 如果直接运行此模块,作为主程序,则执行其中的语句;
- 如果 import 进别的模块,则运行别的模块时不会执行其中的语句。
此语句不充当程序入口的作用。和 C 语言里的 void main() {...} 意义不同!
考虑以下场景:当一个项目有好多 .py 文件时,如果此程序是主程序,那加不加这句都无所谓;如果不是主程序,通常里面都是些定义的类与函数,也没有真正执行的代码,那if __name__ == '__main__':里面的代码是做什么的?答:测试此模块用。只要运行此模块,就会执行测试代码;而真正运行主程序时不会执行它。
7 输入输出
Python 的输入输出有很多方式,这里不讨论由第三方库实现的各种数据的输入输出,只讨论最基本的:
- 标准输入输出:从键盘读取,在终端打印输出;
- 文件输入输出:读取或写入文件。
文件输入输出和 C 语言形式上类似,比较麻烦,我太不常用就不写了。本章只讲标准输入输出。
7.1 input() 与 print()
标准输入输出都是通过几个内置函数实现的。
输入主要靠 input() 函数,效果为:程序在此处暂停,等待用户输入字符串,敲下回车后字符串传入其返回值。input() 函数接受一个字符串参数作为提示语。
输入主要靠 print() 函数。print() 函数非常灵活,可以接任意类型的任意多个参数,输出结果以空格隔开。除字符串外,Python 为所有的类都规定了一套默认的打印格式,在 __print__() 和 __repr__() 方法中定义,可以自行修改。
注意,代码中不能像在提示符下那样变量直接敲回车查看信息。所以直接把 变量 摆在代码里的语句是没有效果的,必须写 print(变量)。
之前的习惯没必要:我喜欢把所有要打印的东西用 str() 函数强制转换成字符串,用加号运算符拼接后再打印。在 print() 中,直接用逗号隔开即可。
7.2 格式化字符串
格式化字符串是指意义是把动的变量统一放后面,不动的字符堆在前面,看起来更美观。字符串的格式化规则都是在 str 类中 format() 方法定义的。用法:在字符串处要填空的位置以{}表示,在方法的参数中填入数据。大括号里面可以:
- 什么也不填:顺序传入参数(即
format()方法的可变参数,也可以传入一整个*元组); - 自然数:按照数字标示的参数位置传入;
- 变量名:应传入带
变量名=的参数(即format()方法内的关键字参数,也可以传入一整个**字典); - 数据格式:以
%开头,不需记忆,因为与 C 语言的表示方法一致。
这样 print() 函数的使用方法是 print('...{}...{\%f}...'.format(A,B))。还有一种更简洁的写法:print(f'...{A}...{B:f}...'),字符串前加 f 表示格式化的字符串。
8 遇到 bug
本节统一讲解一切有关 bug 和遇到 bug 的时候做的事情。
8.1 异常
Python 中的报的错称为异常(exception)。异常本质上是一大类特殊的类,都是一个基类 BaseException 的子类。
常见异常
Python 预定义了各种各样的内置异常,都可在文档中查到。前面有很多地方涉及到了各种异常。这里我只讨论一些经常遇到的:
SyntaxError:语法错误,比如少了冒号、括号不匹配;NameError:使用了未定义的变量;TypeError:类型不匹配的操作;ValueError:值不合适(类型对,但值非法);IndexError:列表/元组下标越界。KeyError:访问字典中不存在的键。AttributeError:对象没有该属性或方法。ZeroDivisionError:除数为零。ImportError/ModuleNotFoundError:导入模块失败。AssertionError:assert 语句失败。
自定义异常
Python 的内置异常有时候不够用,可以自定义异常。
做法:只需定义一个继承异常类的子类。最简单的是直接继承异常的基类,什么事也不做。
class MyError(Exception):
pass自定义异常应当继承 BaseException 下的 Exception,而不是BaseException,BaseException 除了 Exception 里普通的异常外,主要是 KeyboardInterrupt 等系统级别的特殊异常。
异常处理:try 语句
Python 有完善的异常处理机制可供编程人员使用,即 try 语句,可以在代码执行时捕获异常,并采取用户规定的操作。由几部分组成:
try:后面跟要尝试捕获异常的代码;except 异常类名:后面跟捕获到异常时要执行的代码,可以有多个 except。异常类名可以多个用逗号连接,不加它则表示所有异常;else:后面跟没捕获到任何异常后要执行的代码;finally:后面的语句是在执行完上面所有程序后一定要执行的代码。 如果触发不在 except 里指定的异常或者没有异常,程序不会中断;而触发不在 except 里指定的异常,仍然是会报这个异常的错。这两种情况都会触发最后的 finally。
try 语句定义了四种语句,是比较混乱的,即有的情况可以有很多种表达方式,会有些语法冗余。但是编程语言不是追求逻辑的完备性,而是为了使用方便。所以不必纠结定义混乱的问题。
抛出异常:assert, raise 语句
有时候在代码里需要手动触发异常,自己自定义异常也是为了抛出的。抛出异常有专门的语句,平时 Python 报错抛出的异常在 Python 的源码就是用了这些语句:
raise 异常类名:抛出异常;assert ...接一个逻辑表达式,如果为 True 则通过,否则抛出AssertionError异常。它等价于
if not EXPRESSION:
raise AssertionErrorassert 语句的用处:
- 预防未知的错误,在写代码时我们脑海中预判了一些情况下可能出现的问题(例如 0除以0),虽然这些情况可能不会发生,但也可以加条
assert 这些情况在前面以防万一; - 有些机器不满足程序运行的条件,在最前面加条 assert 可以让程序直接报错,而不必等待程序运行后崩溃;
- 调试:见小节 8.2。
上下文管理器:with 语句
with 语句一般就是用于异常处理的,放到这里来讲。
with 语句的控制流如下。以下代码的执行顺序为:
with Class(...) as var:
...- 创建一个 Class 类的实例;
- 调用该实例的
__enter__()方法,返回值赋值给 as 后面的变量var; - 执行主体部分的语句;
- 调用该实例的
__exit__()方法。
可见本质上就是在一段代码前后加上两段代码。但并不是三段代码简单地顺序拼接,它们之间和一个类的实例息息相关。__enter__()和__exit__()方法需要自己定义(称实现上下文管理器),也必须遵循一些规则:例如 __exit__() 必须规定三个有关异常的参数 exc_type、exc_val 和 exc_tb。
可见它适用于对资源进行访问的场合,例如文件操作就是包裹在 with 语句中进行的,file 类就是这里的 Class 类,打开关闭文件都由 file 类定义的上下文管理器控制。自己写的代码根本用不到这东西,只需知道哪些地方最好用 with 包裹,遵守现成的规范即可。
8.2 调试
在 Python 中调试代码有以下几种方式:
print()函数:在合适的位置打印变量的值;- assert 语句:用 assert 后接的逻辑表达式来验证自己的想法和程序实际运行是否一致,不一致则报
AssertionError; - logging 库:专门用于日志的库,其实就是更高级的
print()语句。它可以输出不同样式的信息(DEBUG, INFO, WARNING, ERROR, CRITICAL),也像 assert 一样有开关控制输出哪些信息;不仅可以输出到终端,还能输出到日志文件中; - pdb 调试器:在代码中
import pdb,用pdb.set_trace()语句打断点。 在运行代码时命令加选项-m pdb,代码运行进入调试模式,提示符变成(Pdb)->,可在其中输入 pdb 命令控制调试流程:n:单步执行;l:是查看当前运行到的代码位置;p 变量:查看变量;- …
- IDE 里的调试工具:基本都是 pdb 的图形化实现,它不需要在代码中做任何标记,通过按按钮的方式完成打断点、执行,还能即时查看各种变量。
这些调试方法没有优劣之分,各自都有优缺点。平时使用时应视具体情况选用合适的调试方式:
print()函数可以输出具体信息,assert 则不行。有时候我们需要具体信息,而有时候会看起来太乱;- assert 语句可以全局开关。在运行代码时加参数
-O可以关闭所有 assert(相当于把所有 assert 语句删掉)。用print()函数如果不想调试了则必须删除或注释掉; - logging 库更适合运行时间较长的大型项目中管理日志,对于小代码实在没有必要;
- 在 IDE 里调试的问题是每次都需要手动打断点,不能保存断点信息,也无法输出成文本。更适合临时查看程序执行情况的场景。
Python 官方教程里也介绍了什么时候用什么工具最好,可以参考。
8.3 测试
前面提到在模块的 if __name__ == '__main__':可以用来做测试。Python 中也有专门的 unittest 模块用来做单元测试,我平时用不到,就不作介绍了。
9 附录:其他 Python 标准库与内置函数
Python 标准库与内置函数在上面各章节都有所涉及。其余的暂时列举在这里,只概述其大致用途,使用时现查官方文档,不作过多介绍。
- sys 模块:可以查看当前系统或解释器级别的信息,例如上面见到了
sys.argv; - os 模块:处理文件和目录;
- time, date, datetime 模块:处理时间信息,有专门的时间类表示,也可以整数表示(1970年1月1日后度过的秒数);
time.sleep(secs):可以让程序暂停 secs 秒,比较常用;
- math 模块:提供常用数学函数,处理数学计算。cmath 模块用以处理复数;
- re 模块:使用正则表达式处理文本匹配等问题;
- argparse 模块:为命令行向解释器传参提供了更高级的功能。见我的文章 Python 命令行解析参数;
- json/pickle 模块:都用于保存、加载 Python 变量,前者存的是文本文件(json 格式),后者是二进制文件。文本文件更通用,更易读,但支持类型少,例如不支持 Python 类实例的保存;二进制文件不可读,但支持所有 Python 类型。