- 论文:Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
- 期刊:TMLR 2022
- 作者:德州大学奥斯汀分校等
本文在类别增量(CIL)场景的简单模型 LwF 基础上做了改进,并使用了三个机制,提升了模型的效果:无标签查询数据(QUD)、辅助分类器平衡训练、对抗样本训练。本质上持续学习的重演方法和正则化方法。本文用的几个机制其实是独立的、平行的,作者将其堆叠到持续学习场景中,有点缝合怪行为。
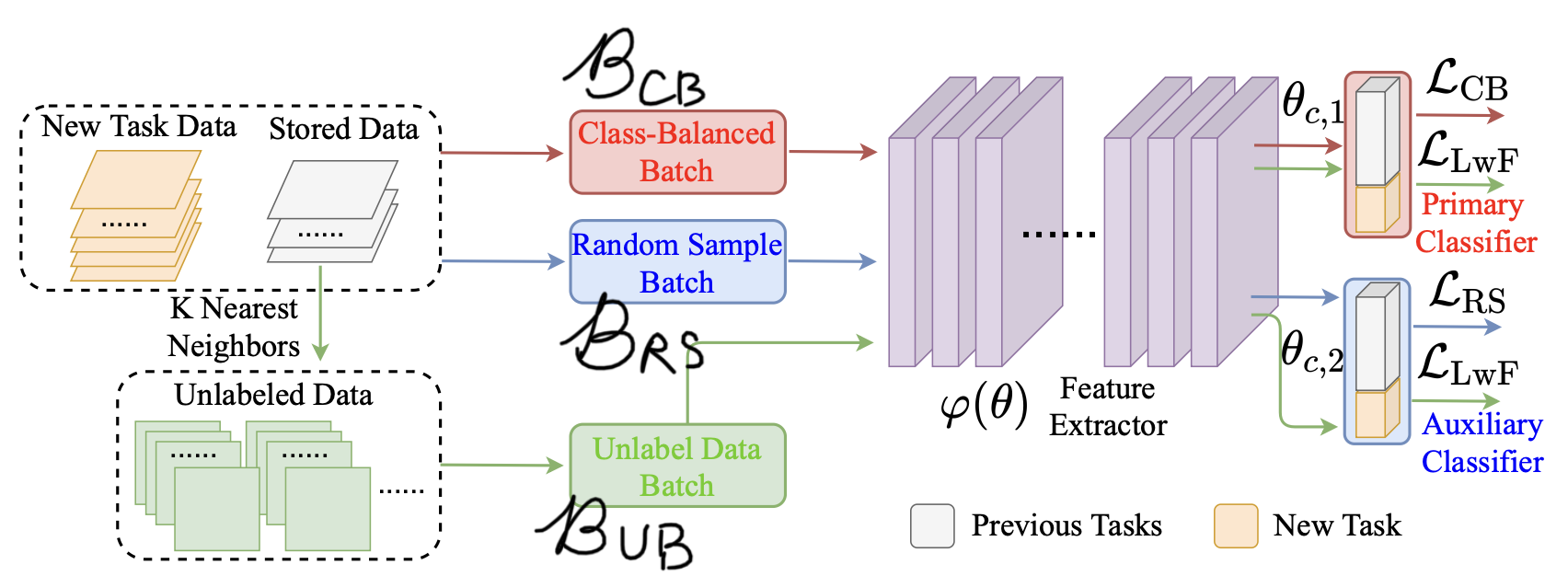
无标签查询数据(QUD)
持续学习重演方法最大的问题是受记忆容量限制,重演数据量不够导致的训练样本不均衡的问题。本文的特色是利用了外部数据库(例如 Google 图片)的数据帮助防止遗忘。查询数据(query data)是一个数据库概念,是指从数据库中按照一定的查询条件抽取的一些数据。
具体来说,在 \(t\) 时刻从外部数据库查询大量与旧任务 \(\tau_1, \cdots, \tau_{t-1}\) 相似的数据。查询的依据是与已经存储的极少的重演数据,拿它当作 anchor(诱饵)钓出与其相似的数据。这些 anchor 设计为每个旧任务固定的数量(由于基数小,线性增长问题不大),每个旧任务的查询数据量也是固定的。注意查询数据都是无标签的。查询有专门的算法(参考信息检索领域知识),不再介绍(本文使用 Google 图片可以使用 Google 相似图片搜索的 API)。
获得了大量无标签查询数据后,最常用的是知识蒸馏或知识迁移方法,通过在损失函数中加入以下正则项:
- 知识蒸馏(KD):\(\mathcal{L}_{\mathrm{LwF}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}\right):=\mathbb{E}_{\mathbf{x} \in \mathcal{U}}\left[\mathcal{K D}\left(\rho\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}, \mathbf{x}\right), \rho(\hat{\boldsymbol{\theta}}, \hat{\boldsymbol{\theta}}_{\mathrm{c}}, \mathbf{x})\right)\right]\),\(\mathcal{U}\) 为无标签查询数据,\(\rho\) 为分类器最后输出的结果(概率值),此正则项让模型在查询数据(代表了旧任务数据)上预测结果尽量向旧模型靠近;
- 知识迁移(KT):\(\mathcal{L}_{\mathrm{LwF}}(\boldsymbol{\theta}):=\mathbb{E}_{\mathbf{x} \in \mathcal{U}}\left[\mathcal{F} \mathcal{T}\left(\varphi(\boldsymbol{\theta}, \mathbf{x}\right), \varphi(\hat{\boldsymbol{\theta}}, \mathbf{x}))\right]\)。它与 KD 的差别在只是让共有网络 \(\varphi(\theta)\) 输出结果靠近,整个损失函数不会更新旧任务的输出头。
这里与 LwF 类似,因为都用了知识蒸馏,但是不一样。LwF 手中只有等当前任务的数据,将其当作旧任务数据作蒸馏。这样不适合 CIL 场景,因为旧模型还没有新任务类别的输出头,无法完成新任务。
关于此方法,我认为可能存在的问题:每次查询的数据是不能存下来的,而每个旧任务 anchor (即查询的依据)是固定的,所以会重复查询相同的数据,查询量也是线性增长的,其实将重演记忆的空间代价转化成了查询的时间代价。
辅助分类器平衡训练
这个机制也是为了解决重演的训练样本不均衡的问题。先不管查询数据,将 anchor 看作重演数据,最简单的重演方法是将新数据和重演数据混合,随机采样 batch 拿来训练。这些重演的 anchor (旧类别)占新数据(新类别)的比例是悬殊的。而有其他的采样方式可以使采样的 batch 类别是均衡的,称为 class-balanced batch,具体见论文中引述的工作。
然后,并不是直接使用 class-balanced batch,随机采样的 random batch 也要用,但单独给它开一个分类头。训练时二者同等重要。这样做的目的是防止 class-balanced batch 过分突出不平衡的那部分少量的数据使其过拟合(起到了隐式的正则化的作用)。损失函数:
\[ \min _{\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}, \boldsymbol{\theta}_{\mathrm{c}, 2}} \mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{CB}}}\left[\mathcal{L}_{\mathrm{CB}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}, \mathbf{x}\right), y\right)\right] +\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{RS}}}\left[\mathcal{L}_{\mathrm{RS}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 2}, \mathbf{x}\right), y\right)\right] \]
但在测试阶段并不参与到分类结果中,即测试阶段的输出只用 class-balanced batch 对应的分类头,称为主分类器(primary classifier),random batch 对应的分类头称为辅助分类器(auxiliary classifier)。个人认为这样做训练与测试阶段不一致,合理性有待讨论,但实际上很多论文都有过这种现象,例如上次的 CAT。
将此机制结合到 QUD 机制,得到了本文的 CIL-QUD 模型:
最终的损失函数:
\[ \begin{aligned} \min _{\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}, \boldsymbol{\theta}_{\mathrm{c}, 2}} \mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{CB}}}\left[\mathcal{L}_{\mathrm{CB}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}, \mathbf{x}\right), y\right)\right] &+\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{RS}}}\left[\mathcal{L}_{\mathrm{RS}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 2}, \mathbf{x}\right), y\right)\right] \\ &+\lambda \cdot\left[\mathcal{L}_{\mathrm{LwF}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}\right)+\mathcal{L}_{\mathrm{LwF}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 2}\right)\right] \end{aligned} \]
对抗样本训练
对抗训练是用来提高模型鲁棒性的一种手段,通过设计在原数据 \(\mathbf{x}\) 上的扰动 \(\mathbf{\delta}\) 得到训练样本(标签 \(y\) 不变),并使用扰动样本训练。一般形式为如下 min-max 式:
\[ \min _{\boldsymbol{\theta}} \mathbb{E}_{(\boldsymbol{X}, y) \sim \mathcal{D}}\left[\max _{\|\boldsymbol{\delta}\| \leq \epsilon} L\left(f_{\boldsymbol{\theta}}(\boldsymbol{X}+\boldsymbol{\delta}), y\right)\right] \]
加到上面的损失函数中,得到本文的 Robust 版模型 RCIL-QUD :
\[ \begin{aligned} &\min _{\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, i}, \boldsymbol{\theta}_{\mathrm{c}, 2}} \mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{CB}}}\left[\max _{\|\boldsymbol{\delta}\|_{\infty} \leq \epsilon} \mathcal{L}_{\mathrm{CB}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 1}, \mathbf{x}+\boldsymbol{\delta}\right), y\right)\right]+\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{B}_{\mathrm{RS}}}\left[\max _{\|\boldsymbol{\delta}\|_{\infty} \leq \epsilon} \mathcal{L}_{\mathrm{RS}}\left(f\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}, 2}, \mathbf{x}+\boldsymbol{\delta}\right), y\right)\right]\\ &+\gamma_1 \cdot \mathcal{L}_{\mathrm{LwF}}^{\mathrm{R}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}\right)+\gamma_2 \cdot \mathcal{L}_{\mathcal{R} \mathcal{T C}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}\right) \end{aligned} \]
其中查询数据构造的正则项 $ {}^{}(, )$ (注意这里把 \(\boldsymbol{\theta}_{\mathrm{c}, 1},\boldsymbol{\theta}_{\mathrm{c}, 2}\) 合为一项了),也一样分两种:
- Robust 版知识蒸馏(RKD):\(\mathbb{E}_{\mathbf{x} \in \mathcal{U}}\left[\max _{\|\boldsymbol{\delta}\|_{\infty} \leq \epsilon} \mathcal{K} \mathcal{D}\left(\rho\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}, \mathbf{x}+\boldsymbol{\delta}\right), \rho\left(\hat{\boldsymbol{\theta}}, \hat{\boldsymbol{\theta}}_{\mathrm{c}}, \mathbf{x}\right)\right)\right]\)
- Robust 版知识迁移(RFT):\(\mathbb{E}_{\mathbf{x} \in \mathcal{U}}\left[\max _{\|\delta\|_{\infty} \leq \epsilon} \mathcal{F} \mathcal{T}(\varphi(\boldsymbol{\theta}, \mathbf{x}+\boldsymbol{\delta}), \varphi(\hat{\boldsymbol{\theta}}, \mathbf{x}))\right]\)
最后又额外引入了一个正则项,能让无标签数据在增强鲁棒性上发挥更大作用(无标签数据已经用在了 \(\mathcal{L}_{\mathrm{LwF}}^{\mathrm{R}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}\right)\) 中):(此方法称为 TRADES,不是作者提的,引用了另一篇 SOTA 的文章 Theoretically principled trade-off between robustness and accuracy)
\[ \mathcal{L}_{\mathcal{R} \mathcal{T C}}\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}\right) =\mathbb{E}_{\mathbf{x} \in \mathcal{U}}\left[\max _{\|\boldsymbol{\delta}\|_{\infty} \leq \epsilon} \mathcal{K} \mathcal{L}\left(\rho\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}, \mathbf{x}+\boldsymbol{\delta}\right), \rho\left(\boldsymbol{\theta}, \boldsymbol{\theta}_{\mathrm{c}}, \mathbf{x}\right)\right)\right] \]
道理很简单,无论有无标签,对抗训练都希望扰动之后预测值不变:对有标签数据,不变的是已知的预测标签 \(y\),所以 \(\mathcal{L}(\cdot, \cdot)\) 第二个位置填 \(y\);对无标签数据,就填扰动前的输出了。(有标签数据也可以这样填,但是纯粹找麻烦了。)