This paper is published in Nature 2024, which is the one of most renowned academic journals in all science subjects. It is unusual for paper in continual learning which such a specific area in AI to be published here. The authors are PhD students in University of Alberta supervised by one of the greatest AI scientists, Richard Sutton, one of the founders in reinforcement learning.
The paper is about the lack of plasticity problem as more tasks arrive. Interestingly, it matches my current research on network capacity problem (that I refer to in my paper) in architecture-based continual learning approaches. It concerns the balance of stability-plasticity, where most of continual learning works try to get more stability for the model to address catastrophic forgetting, while we concern the other way. In the paper it said clearly: “loss of plasticity is different from catastrophic forgetting.” Also they have the same idea as I was experimenting on longer task sequences than usual in my last paper, as it said in the paper: “the experiments must be run long enough to expose long-term plasticity loss.” Their group has focused on this topic of loss of plasticity for years and published several other papers on that:
However, there is a huge difference between the loss of plasticity that they and I refer to. I limit the scope to that the parameter isolation approach in architecture-based continual learning faces the moment when the parameter space runs out, thus there is no capacity for future tasks, which is a form of losing plasticity in the wider sense of stability-plasticity balance in continual learning. This paper observed a big problem existing in any continual learning approach for the first time, that the deep learning itself makes the neural network model lose plasticity gradually as more data come into training. In the core experiment of this paper that discovered the problem, it simply applied Finetuning baseline (nothing special applied for continual learning) on TIL and CIL settings, and found that even the performance on the new task gradually degenerates away from what it should achieve (note that the y-axis in the figure below represents accuracy on the new task rather than average accuracy over seen tasks).
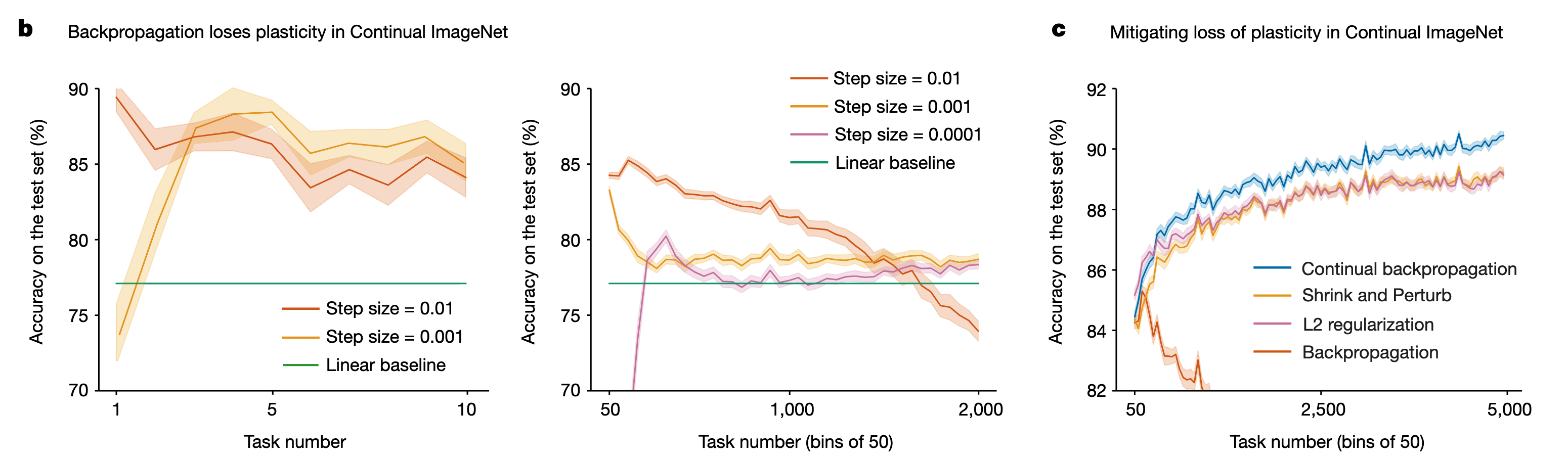
It’s very fundamental regarding the entire area of continual learning, which I can’t even believe it in the first place, and I think that makes it deserve the publication on Nature. Now there’s another important thing to consider when we study continual learning with long task sequences.
If we think about the connection between these two phenomena of loss of plasticity, I’d say the general one from this paper is hidden under the explicit one specifically for architecture-based. If any parameter in architecture-based approaches is trained repeatedly over time, it could face the general problem as well. But apparently the explicit one has priority to be addressed in architecture-based continual learning, so I only look for ideas that might be useful for that explicit thing I’ve been following at this point, rather than concerned with the general problem.
Looking into their ideas, they proposed an algorithm called continual backpropagation, which also seems to be a fundamental solution for continual learning by modifying the underlying backpropagation mechanism. If we look closer, the idea is pretty simple: they think the cause of plasticity loss is that 1. large weights reduce plasticity; 2. some weights stay dormant. Their algorithm defines a contribution utility measure on units taking into account both causes, and reinitialise the least useful ones periodically. It is basically selective reinitialisation.
The reinitialisation helps release network capacity anyway though it means differently in this paper. Therefore it applies to what I want to improve for HAT, one work of which is AdaHAT. For example, reinitialise units that are least useful to previous tasks to make the way for future tasks. At the same time, I had found the learnable masks of HAT hardly update themselves showing great dormance, which could also be solved from reintialising potentially.
In summary, this is a very significant paper to read and also good to learn some ideas for algorithms to release network capacity and reduce the loss of plasticity.
Back to top