My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Vision Transformer (ViT) is a neural network architecture that applies the Transformer model, originally designed for natural language processing, to image recognition tasks by treating images as sequences of patches.
ViT is more like a vision version of BERT, instead of Transformer. Like BERT, ViT is also an encoder-only architecture, and follows the pre-training and fine-tuning paradigm.
ViT was proposed by researchers at Google in a 2020 paper (Dosovitskiy et al. 2020). The paper introduced the idea of applying the Transformer architecture, which had shown great success in NLP tasks, to the domain of computer vision.
By the end of 2020, classical convolutional neural networks (CNNs) like ResNet and EfficientNet were the dominant architectures for image recognition tasks. However, these models had limitations in capturing long-range dependencies in images due to their localized receptive fields. At the same time, Transformers had revolutionized NLP by effectively modeling long-range dependencies in text data. This inspired researchers to explore whether the Transformer architecture could be adapted for image data, leading to the development of ViT.
ViT demonstrated that Transformers could outperform traditional CNNs on image recognition tasks when trained on large datasets. This was a significant breakthrough, as it challenged the prevailing notion that CNNs were the best choice for image-related tasks. ViT’s success opened up new avenues for research in computer vision, leading to the development of various Transformer-based architectures for different vision tasks, such as object detection and segmentation.
ViT also highlighted the importance of large-scale pre-training and transfer learning in computer vision, similar to the trends seen in NLP. This has influenced the design of subsequent models and has led to a greater emphasis on leveraging large datasets for training vision models.
ViT paved the way for multi-modal models that combine vision and language, such as CLIP and DALL-E, which have had a profound impact on the field of AI.
BERT is a embedding model. ViT adapt the input and output format of the BERT model to handle image data. It just takes in images (in a patch format) and outputs embeddings.
Input:
- An image of any size is divided into fixed-size patches (e.g., 16x16 pixels).
- A special
[class]token is added to the sequence of patch embeddings for classification tasks.
Output:
- A sequence of contextualized embeddings
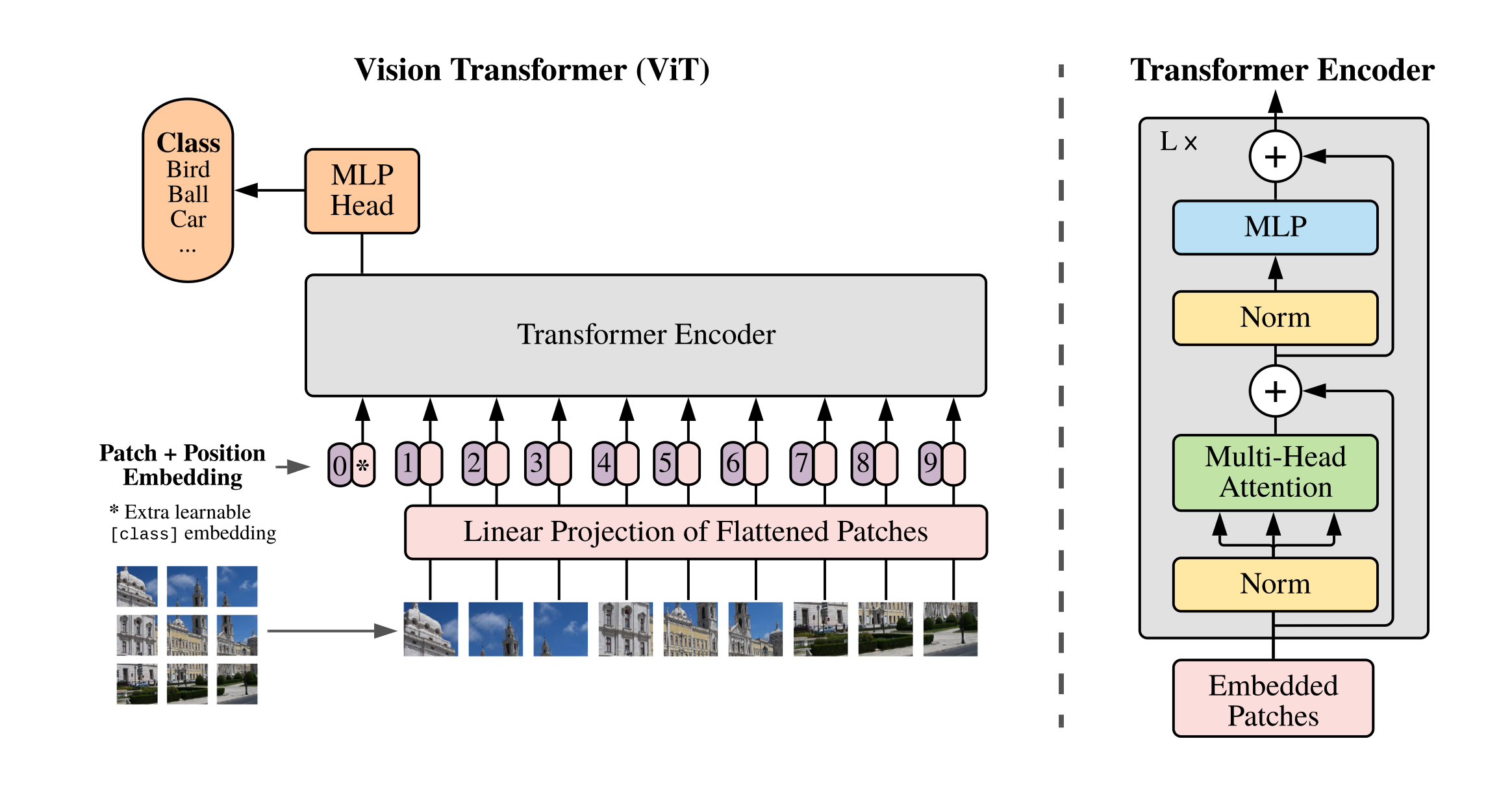
Like BERT, ViT is also simply a stack of Transformer encoder layers. The input embeddings are fed into multiple layers of Transformer encoders, which consist of multi-head self-attention mechanisms and feed-forward neural networks. Please refer to AI Concept Takeaway: Transformer for more details about the Transformer encoder.
There are similarities and also some differences between ViT and BERT so that ViT can handle image data:
- Patch Embedding: Unlike the embedding layer in Transformer or BERT that maps discrete tokens to dense vectors, ViT uses a linear projection to convert image patches into embeddings, because the input data is continuous (pixel values) rather than discrete (word tokens). Each patch is flattened into a vector and then projected into a higher-dimensional space. The weights of this linear projection are learned during training.
- Positional Embedding: Similar to Transformer and BERT, ViT adds positional embeddings to the patch embeddings to retain spatial information about the patches’ locations within the original image.
The choice of patch size is a hyperparameter that can affect the model’s performance and computational efficiency. Common choices for patch sizes are 16x16 or 32x32 pixels. Smaller patches can capture finer details in the image but result in longer sequences, which can increase computational complexity. Larger patches reduce the sequence length but may lose some spatial information.
The patch is not allowed to be pixel-level (1x1), because that would create an extremely long sequence, making the self-attention computation infeasible. The patch is also not allowed to be the entire image, because that would lose all spatial information.
The choice of patch size is a hyperparameter that can affect the model’s performance and computational efficiency. Common choices for patch sizes are 16x16 or 32x32 pixels. Smaller patches can capture finer details in the image but result in longer sequences, which can increase computational complexity. Larger patches reduce the sequence length but may lose some spatial information.
ViT follows the pre-training and fine-tuning paradigm.
- During pre-training, ViT is trained on large image datasets, which allows ViT to learn general visual representations.
- During fine-tuning, ViT is connected to task-specific output heads that output discrete labels for specific CV tasks. The entire model (ViT + output heads) is then trained on labeled datasets for the specific tasks.
ViT itself cannot be supervisedly trained, because it outputs embeddings instead of discrete labels, which are not available in any CV dataset. To utilize image data, ViT has to connect the output embeddings to some output heads that output discrete labels.
In the original paper (Dosovitskiy et al. 2020), the author proposed pre-training ViT simply on the image classification task. The output head is a feed-forward neural network followed by a softmax classifier that takes in the embedding corresponding to the [class] token and outputs a probability distribution over the predefined image classes. The loss function is the cross-entropy loss between the predicted class and the true class.
Later works have explored more advanced self-supervised pre-training strategies for ViT, such as masked patch modeling (MIM) and contrastive learning, to further improve its performance on downstream tasks.
ViT can be fine-tuned for a wide range of CV tasks, including but not limited to:
- Image Classification: Assigning a label to an entire image. We have discussed this above.
- Object Detection: Identifying and localizing objects within an image.
- Image Segmentation: Classifying each pixel in an image to delineate object boundaries. …