My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
BERT (Bidirectional Encoder Representations from Transformers) is a neural network architecture designed for natural language processing (NLP) tasks. It is based on the Transformer architecture, specifically the encoder part of the Transformer.
BERT follows the pre-training and fine-tuning paradigm, where a model is first pre-trained on a large corpus of text data to learn general language representations, and then fine-tuned on specific downstream tasks such as text classification, named entity recognition, and question answering.
BERT was proposed by researchers at Google in a 2018 paper (Devlin et al. 2019). Transformer was originally proposed in 2017 (Vaswani et al. 2017) and became very popular in NLP. However, the original Transformer was designed for sequence-to-sequence tasks, such as machine translation, where both the encoder and decoder are used. For many NLP tasks, only the encoder part is needed. Therefore, BERT uses only the Transformer encoder layers, and adopts the pre-training and fine-tuning paradigm to make it suitable for various NLP tasks.
BERT achieved state-of-the-art results on a wide range of NLP benchmarks at the time of its release, demonstrating the effectiveness of the pre-training and fine-tuning paradigm. It has since become a foundational model in NLP, inspiring numerous subsequent models and research in the field. BERT’s success has also led to the development of various variants and extensions, such as RoBERTa (Liu et al. 2019), ALBERT (Lan et al. 2019), and DistilBERT (Sanh et al. 2019), which further improve upon its architecture and training methods.
Moreover, BERT paved the way for the adoption of large-scale pre-trained language models in various applications, including chatbots, virtual assistants, and information retrieval systems. Its influence extends beyond NLP, as similar pre-training techniques have been applied to other domains, such as computer vision and speech recognition. Later large language models, such as GPT series (Brown et al. 2020), also build upon the concepts introduced by BERT, further advancing the field of natural language processing.
BERT is a embedding model. It just takes in text and outputs embeddings.
Input:
- A sequence of symbol tokens (words, subwords, or characters)
- The first token is always a special token
[CLS], which is a placeholder for classification tasks. - There is another special token
[SEP]to separate two sentences, if any.
- The first token is always a special token
Output:
- A sequence of contextualized embeddings
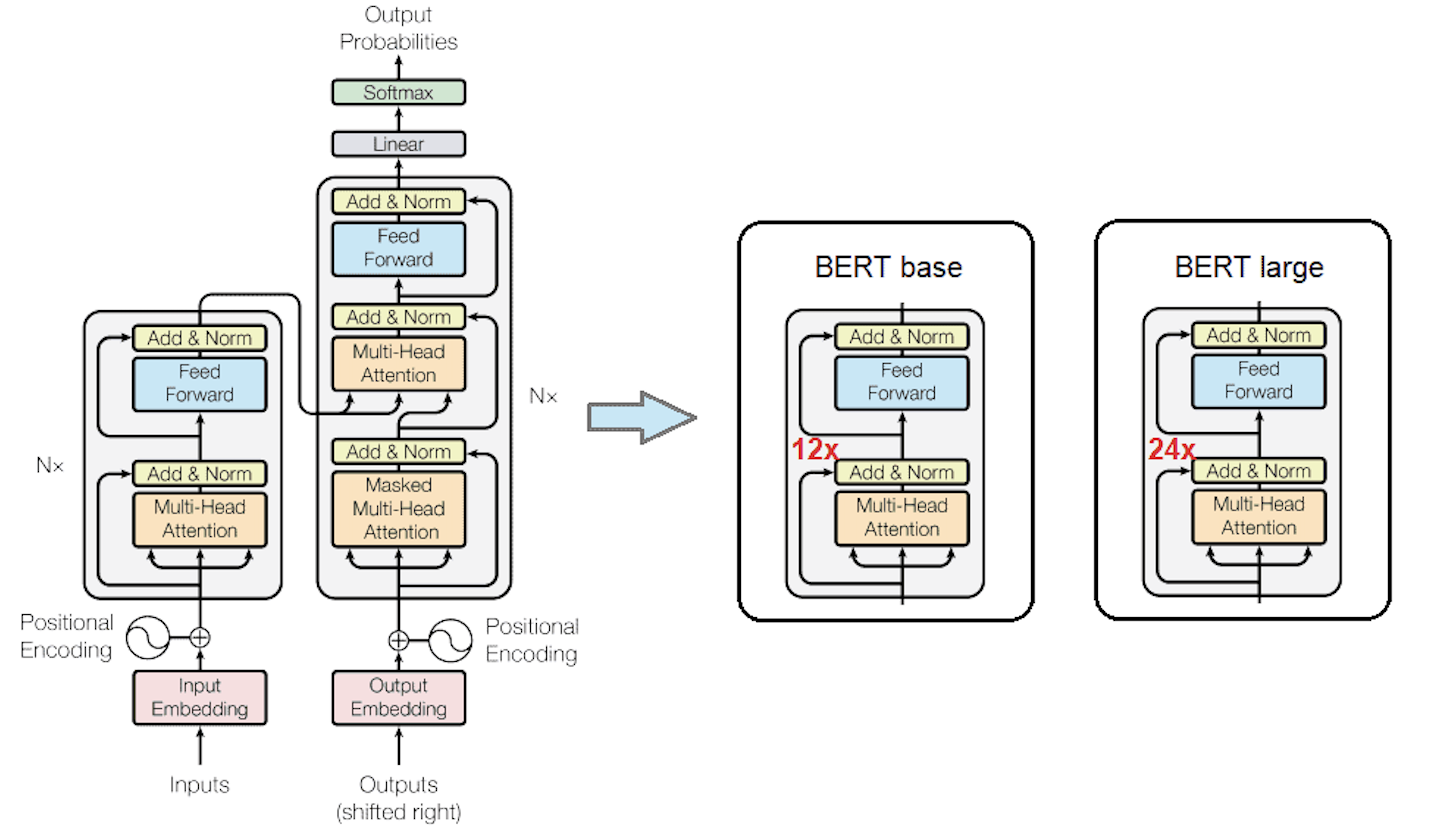
BERT is simply a stack of Transformer encoder layers. The input embeddings are fed into multiple layers of Transformer encoders, which consist of multi-head self-attention mechanisms and feed-forward neural networks. Please refer to AI Concept Takeaway: Transformer for more details about the Transformer encoder.
There are minor differences between BERT and the original Transformer encoder architecture:
- Input Embeddings: BERT adds additional segment embeddings on top of the token embeddings and position encodings. (Position encodings are also called position embeddings in BERT.)
- BERT uses 12 layers of Transformer encoders for the base model and 24 layers for the large model, while the original Transformer uses 6 layers. BERT is deeper to capture more complex language representations.
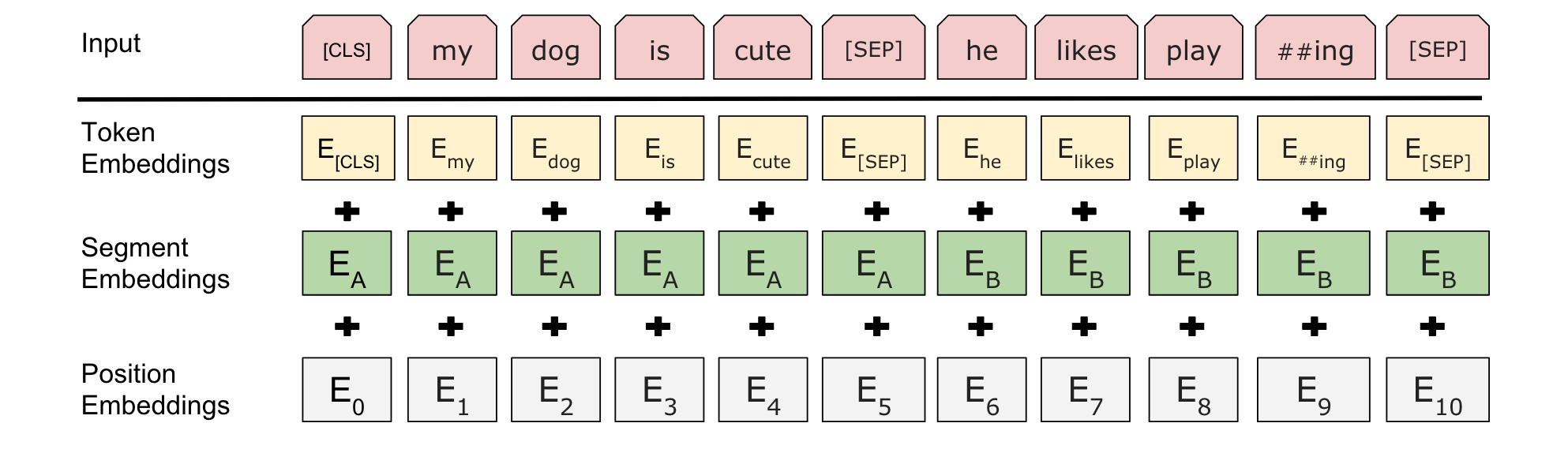
Since BERT also supports tasks that take in multiple sentences as input, such as the next sentence prediction (NSP) task during pre-training, BERT needs a way to distinguish between the two sentences. The segment embedding is added to each token embedding to indicate which sentence the token belongs to.
The segment embedding is a learned embedding that is added to the token embedding and position embedding. For example, if the input consists of two sentences A and B, there will be two segment embeddings:
BERT follows the pre-training and fine-tuning paradigm.
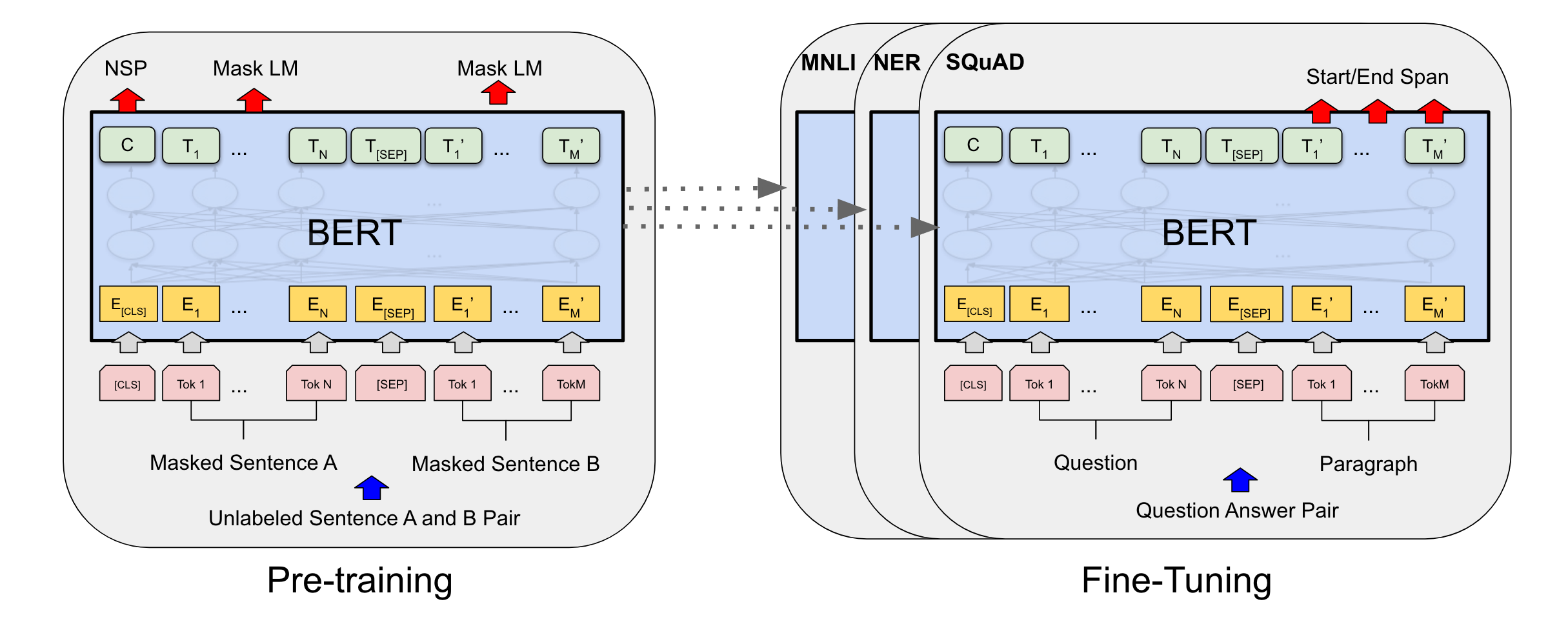
- During pre-training, BERT is trained on large text corpora, which allows BERT to learn general language representations.
- During fine-tuning, BERT is connected to task-specific output heads that output discrete labels for specific NLP tasks. The entire model (BERT + output heads) is then trained on labeled datasets for the specific tasks.
First, BERT itself cannot be supervisedly trained, because it outputs embeddings instead of discrete labels, which are not available in any NLP dataset. To utilize text data, BERT has to connect the output embeddings to some output heads that output discrete labels.
Second, pre-training is usually done on large text corpora. These data are usually collected from the web, naturally without any labels. They are constructed as the inputs
In the original paper (Devlin et al. 2019), the author proposed pre-training BERT with two self-supervised tasks:
- Masked Language Modeling (MLM): Randomly mask some tokens in the input sequence (substitute tokens with a special token
[MASK]), and train BERT to predict the masked tokens based on the surrounding context. This allows BERT to learn bidirectional context representations. - Next Sentence Prediction (NSP): Given two sentences, train BERT to predict whether the second sentence follows the first one in the original text. This helps BERT understand the relationship between sentences.
BERT is considered bidirectional because it uses the entire input sequence to compute the representation of each token, allowing it to capture context from both the left and right sides of the token. Take the MLM task as an example. When predicting a masked token, BERT can attend to all other tokens in the sequence, both before and after the masked token, to gather contextual information. As for Transformer architecture, although the self-attention mechanism allows each token to attend to all other tokens in the sequence, it still focuses on predicting the last token in the decoder, which is one side only.
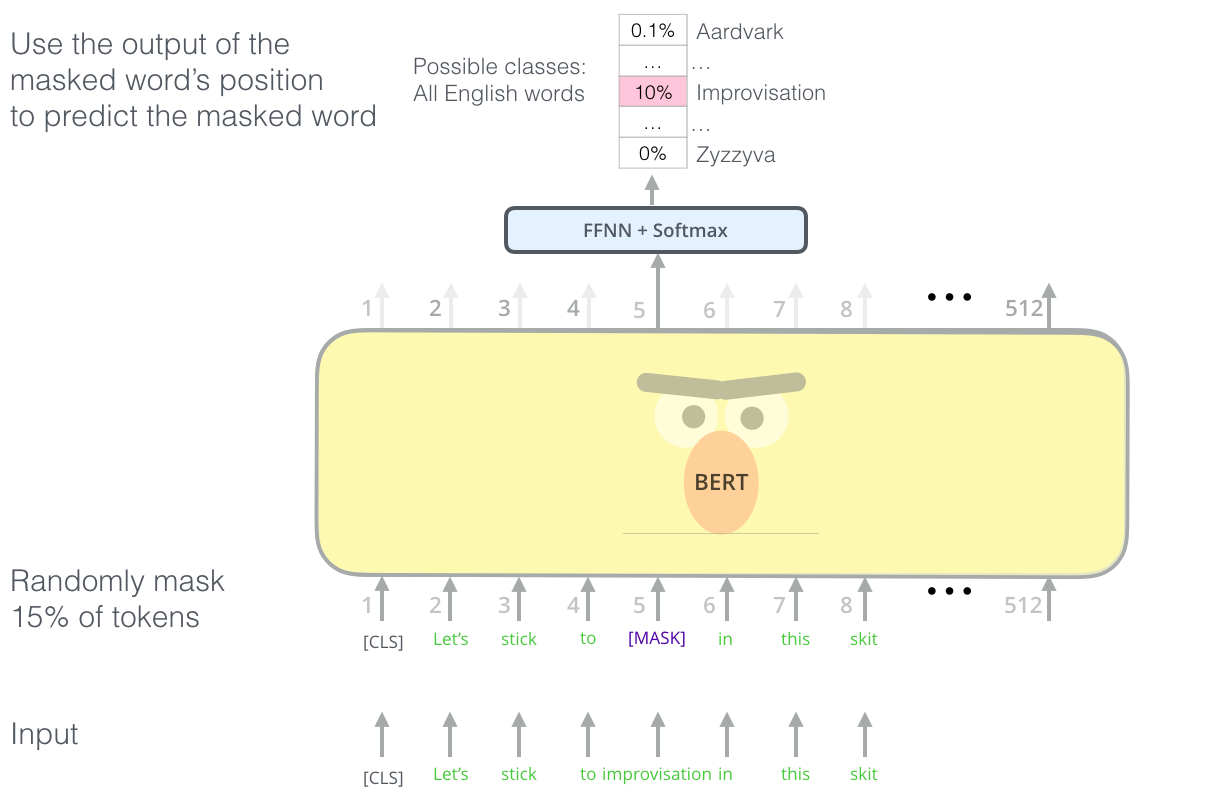
In MLM task, the masked sequence is fed into BERT, which outputs a sequence of embeddings. The embedding corresponding to the masked token is then fed into a feed-forward neural network to further process the information, then softmax classifier to predict the original token. The loss function is the cross-entropy loss between the predicted token and the original token.
Note that the output head is applied to each masked token embedding independently. Therefore, the MLM task can mask multiple tokens in the input sequence, and BERT can predict all masked tokens simultaneously. The output head is applied to each masked token embedding independently, similar to the batch processing of data in neural networks. Therefore, the input to the output head can be a matrix of embeddings, and the output can be a matrix of predicted token probabilities.
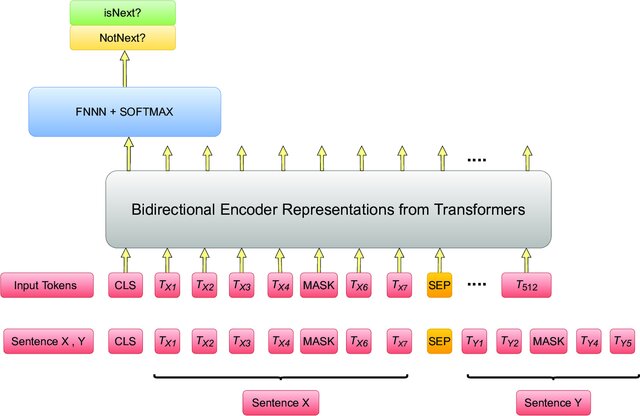
In MLM task, the two sequence concatenated by a special token [SEP] is fed into BERT, which outputs a sequence of embeddings. Note that there is always a placeholder token [CLS] at the beginning of any BERT input sequence. The embedding corresponding to the [CLS] token is then fed into a feed-forward neural network to further process the information, then Sigmoid classifier to output a binary label: whether the second sentence follows the first one. The loss function is the cross-entropy loss between the predicted label and the original label.
BERT is pre-trained on the combination of MLM and NSP tasks simultaneously, because different output heads are used for each task. The input sequence are pairs of sentences, where 50% of the time the second sentence follows the first one, and 50% of the time it does not. Randomly mask some tokens in the input sequence. The entire input sequence is fed into BERT, which outputs a sequence of embeddings. The embedding corresponding to the masked token is fed into the MLM output head to predict the original token, and the embedding corresponding to the [CLS] token is fed into the NSP output head to predict whether the second sentence follows the first one.
The total loss function is the sum of the losses from both tasks:
BERT can be fine-tuned for a wide range of NLP tasks, showing its versatility, including but not limited to:
- Text Classification: Sentiment analysis, spam detection, topic classification, etc. The output head is a feed-forward neural network followed by a softmax classifier that takes in the embedding corresponding to the
[CLS]token and outputs a probability distribution over the predefined classes. - Named Entity Recognition (NER): Identifying and classifying named entities in text. The output head is a feed-forward neural network followed by a softmax classifier that takes in each token embedding and outputs a probability distribution over the predefined entity classes for each token.
- Paraphrase Detection: Determining whether two sentences have the same meaning. The output head is a feed-forward neural network followed by a Sigmoid classifier that takes in the embedding corresponding to the
[CLS]token and outputs a binary label. …
```
Back to top