My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Multi-Task Learning (MTL) is a machine learning paradigm that allows a machine learning model to learn multiple tasks together.
Not to confuse with multi-label learning, which belongs to single-task classification problem where a single input can have multiple labels. Some might use “multi-task” to describe multi-label learning, such as this. That is because multi-task learning is sometimes a broader concept consisting of SIMO (Single Input Multiple Output) and MIMO (Multiple Input Multiple Output) learning, where SIMO is multi-label learning and MIMO is this multi-task learning. In this article, I will focus on the latter.
The objective is to improve average performance across all tasks.
Moreover, multi-task learning is more about knowledge sharing, i.e. to improve over single-task learning of all tasks independently (I refer to this as independent learning), and to promote greater generalisation ability.
This is thoroughly discussed in my article about continual learning.
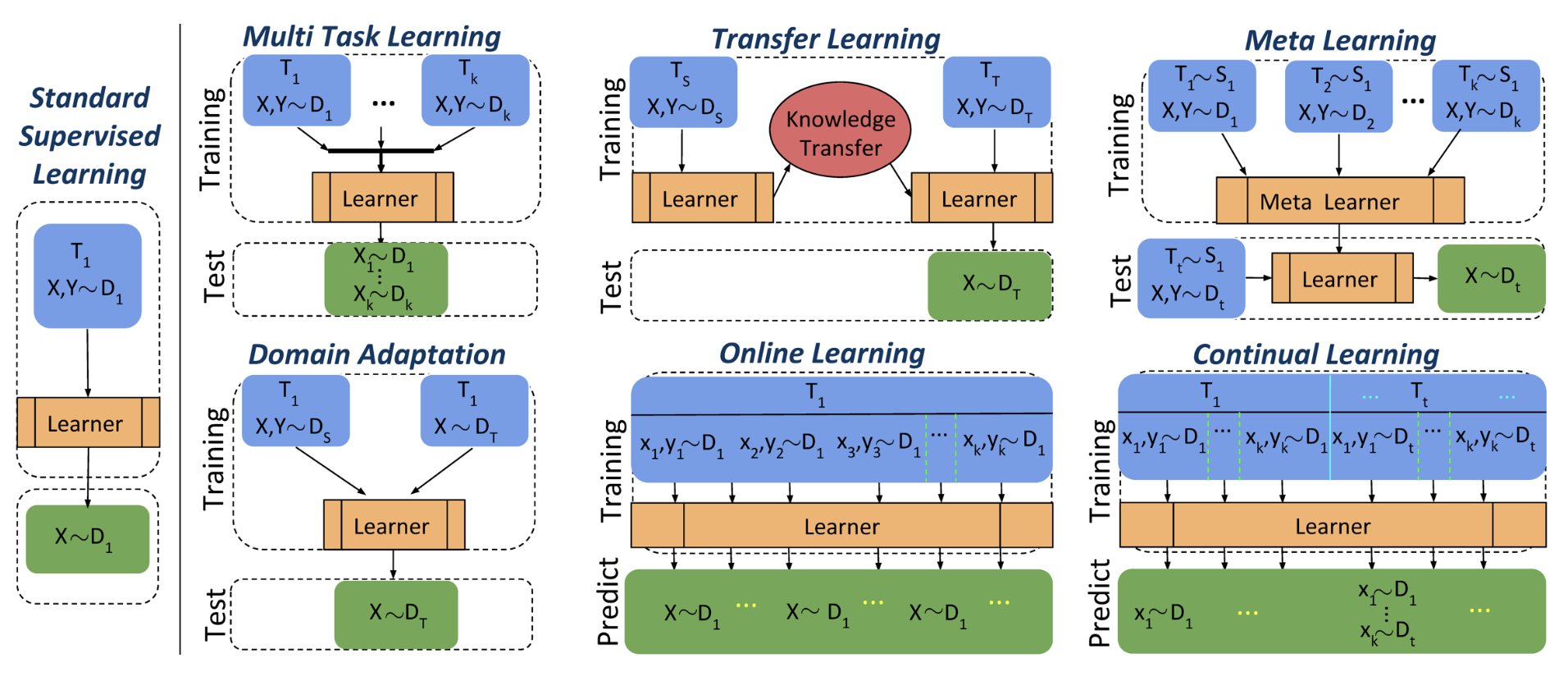
We limit our scope to classification problem. Multi-task learning is a machine learning paradigm:
Inputs:
Training data of tasks
A initialized machine learning model
Outputs:
- Trained model