1 Introduction
Batch normalization (BN) is a very useful training technique that can greatly benefit the training of deep neural networks. However, HAT architecture is incompatible with the original batch normalization.
When we apply pretrained weights to HAT, we found batch normalization layer parameters are key in improving the performance of HAT-based continual learning approaches.
2 Methodology
2.1 Original Batch Normalization
Please refer to the my other post explaining batch normalization.
2.2 The Incompatibility of Original Batch Normalization with HAT Architecture
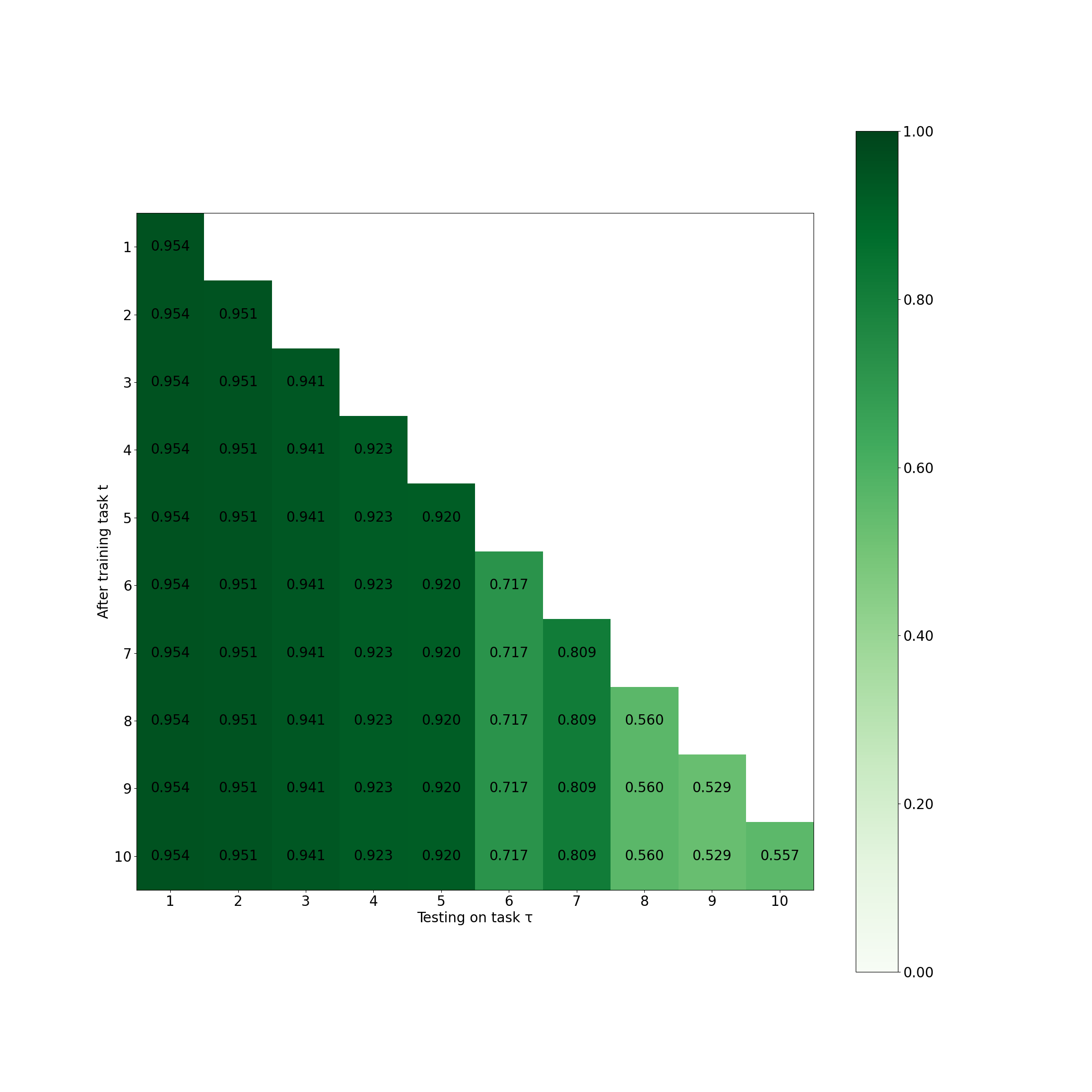
The original HAT architecture is incompatible with batch normalization.
This is demonstrated by irregular behavior of HAT with the original batch normalization:


2.3 Adaptation to HAT Architecture
Key idea: make batch normalization task-specific.
- Batch normalization must lie between the weighted layer and activation, and before the mask. We have experimented with placing batch normalization after the mask, and it doesn’t work.
- When calculating the mean and variance, only consider the neurons that are selected by the current task \(t\):
\[\mu_{l,i} = \frac{1}{\sum_i{m^t_{l,i}}} \sum_{n=1}^{N} z_{l,i} m^t_{l,i},\ \sigma_{l,i}^2 = \frac{1}{\sum_i{m^t_{l,i}}} \sum_{n=1}^{N} ( z_{l,i}m^t_{l,i} - \mu_{l,i})^2\]
- Use task specific \(\boldsymbol{\gamma}_l^t\) and \(\boldsymbol{\beta}_l^t\): \(\hat{z}_{l,i} = \hat{\gamma}_{l,i}^t \tilde{z}_{l,i} + \hat{\beta}_{l,i}^t\)
- Binary mask the parameters \(\hat{\gamma}_{l,i}^t = \gamma_{l,i}^t \cdot m^t_{l,i}\) and \(\hat{\beta}_{l,i}^t = \beta_{l,i}^t \cdot m^t_{l,i}\) to be \(0\) (works the same as bias mask) for the neurons that are not selected by the current task \(t\). Adopt similar gradient adjustment like AdaHAT and FG-AdaHAT.
- Another way: use separate independent batch normalization layers for each task, since it has only neuron-level parameters instead of parameter-level. We can accept this parameter growing.
3 Questions
Extend to more than CNN, ResNet? To transformer? To better form a paper?
What the difference between batch normalization before and after the mask?
What about layer normalization (average on neurons instead of batches)?
Is it enough to publish a paper as a work? Isn’t it just HAT mechanism itself on batch normalization layer?
How to load pretrained weights of batch normalization layers?