本文是我学习 LangChain 的一些笔记和心得。LangChain 是一个开源 Python 框架1,旨在简化构建由大型语言模型(LLMs)驱动的应用程序的过程。它提供了各种工具和组件,帮助开发者更高效地利用 LLMs 的强大功能。
9月份之后,我开始找工作,探索了各种方向后,发现对 AI agent 相关的工作机会很感兴趣,也是最适合我简历情况的(做 AI 的博士,但科研不太涉及前沿的大模型,但写过完整的 Python 包,工程经验丰富)。这篇笔记也是我对 AI agent 领域的一个入门和了解,同时也是在准备面试。
参考资料有:
- LangChain 官方文档
- DeepLearning.AI 的 LangChain 课程,由吴恩达(Andrew Ng)和 LangChain 的创始人一起讲解
本文在近期(2025年9月-10月)持续更新。
1 LangChain 的设计动机
几年前,大模型刚开始火起来的时候,主要的应用是 AI 聊天助手,比如 ChatGPT。这是大语言模型最直接的任务——生成文本。用户输入一个问题,模型生成一个回答。当时 ChatGPT 的表现轰动了一时,大家都在讨论它的强大,关注点也都在这个任务上。
随着时间的推移,人们开始思考这个任务衍生出来的事情了。大语言模型能根据输入生成任何想要的文本,如果仔细想想,这个可不是 “回答问题” 这么简单,因为除了自然语言,很多东西都是文本,比如代码、计算机指令、数学公式、化学分子式、HTML 网页、JSON 数据等。因为可以生成代码文本,所以有了像 Cursor、GitHub Copilot 这样的代码生成工具,帮助程序员写代码。因为可以生成数学公式,所以大模型可以帮你解数学题。因为有了 HTML 网页和 JSON 数据,所以大模型可以帮你写网页,甚至帮你写爬虫程序,帮你从网上搜集信息。那么,因为可以生成计算机指令,所以大模型还能干什么呢?答案是:让大模型直接操作计算机。因为,我们看得见的是操作鼠标和键盘,但所有的操作,最终都会被转换成计算机指令。
然而,计算机指令有如下几个特点:
- 必须非常精确,不能有任何歧义,才能达到预期的效果;
- 需要多步操作,才能完成一个复杂的任务,比如安装软件、配置环境、运行程序等;
- 在每一步操作时,通常需要结合系统的环境信息,才能正确执行,比如当前目录、环境变量、已有文件等;
- 每一个系统都有自己的语法和规则。对于操作系统,Windows、Linux、macOS 都有不同的命令行工具和命令;对于软件,每个都有自己的一套 API;
- 计算机指令是直接作用于机器的,不像自然语言是给人看的,可能会有危险性,可能会删除文件、修改系统设置、访问隐私数据等;
- 可能要与外部系统交互,比如数据库、API、网络等。
正式因为这些特点,丢给 AI 聊天助手,让他直接生成计算机指令并执行,会有很多问题:
- 不精确:大模型生成的东西本身偏向自然语言,可能不够精确,或者有歧义,导致执行结果不符合预期;
- 无法了解环境:如果不借助工具转换,大模型是无法获取当前系统的环境信息的,导致生成的指令可能不适合当前环境。你可能想到,可以提供截图,但这也有很大的问题:截图的本质是图片像素,信息并不精确,而且非图形界面也没办法截图;
- 不完整:大模型可能无法生成完整的多步指令序列,即使生成了,也可能因为缺少上下文信息生成错误;
- 不兼容:大模型可能不知道当前系统的具体语法和规则,生成的指令可能不适合当前系统,导致执行失败;
- 不安全:不精确导致了大模型可能会生成危险的指令,导致系统崩溃、数据丢失等问题;
- 外部系统无法交互:大模型在不借助工具的情况下,无法直接与外部系统交互,生成的指令可能无法正确访问数据库、API、网络等资源。
所以,要让大模型直接操作计算机,必须要有一个中间层,来系统地解决和处理这些工程性问题,没法通过现在的 AI 聊天助手这种逻辑一步完成这件事情。
LangChain 就是这样一个中间层,它是一个开发框架,一边连接大模型提供的 API,一边连接计算机这边各种工具和系统,即指令的 API,从而打通大模型和操作计算机之间的渠道。具体来说:
- 工具调用:通过工具(tool)的方式,把数据库、API、搜索引擎、代码执行器等外部能力暴露给大模型,大模型只需要决定“什么时候调用哪个工具”,而不需要展开成精确的自然语言,从而提高了精确性。(即使展开成了自然语言,也有解析器可以清洗、提取关键词)这些工具也会把当前系统的环境信息传递给大模型,帮助其生成更合适的指令。此外,外部系统也属于工具的范畴,大模型可以通过调用工具来访问外部系统;
- 多步推理:LangChain 提供了 chain 和 agent 的机制,支持将一个复杂的任务拆解成多个简单的步骤,每个步骤由一个独立的组件来完成,然后将这些组件串联起来,由大模型逐步调用工具和生成结果,形成一个完整的工作流。正如 LangChain 名字所述,它的核心理念是就是链式思维(chain of thought),LangChain 在这里面扮演的角色就是管家或者调度系统;
- 可扩展性和兼容性:不同的操作系统、不同的 API,都可以通过自定义的 tool 或 chain 接入 LangChain,让大模型具备可移植性,而不用硬编码;
- 安全性:因为 LangChain 是中间层,开发者可以在执行指令前加上验证、沙箱、过滤等机制,避免大模型直接下发危险命令。
最终,通过上述工程化的设计,LangChain 可以把大模型从“语言生成工具”升级为“通用智能体”,让它能安全、可靠地操作现实世界中的工具和系统。大模型在 LangChain 中的角色只是一个通用推理引擎,即大脑。现在,很多 AI agent 的实现,都是基于 LangChain 或者类似的框架,LangChain 是其中最有代表性的一个。
2 LangChain 下的 AI 聊天助手
上面说了,LangChain 让大模型从 AI 聊天助手升级成了可以操作计算机的 AI agent,是向上升级的。所以,LangChain 也可以用来做 AI 聊天助手,这是它最基础的功能,也是首先要入门的事情,即 LangChain 的 Hello World。
这里的 AI 聊天助手,形式上与 ChatGPT 就不一样了,ChatGPT 是一个完整的产品,而 LangChain 只是一个框架,开发者需要自己搭建前端界面、后端服务等。如果用 LangChain 只写 AI 聊天助手核心的部分,就只能在命令行交互了。
在我们使用 ChatGPT 这类 App 时,所有的操作都是在 App 里点击完成的,而在 LangChain 里,都是通过代码来完成的。这些操作包括:
| 操作内容 | ChatGPT 里(图形界面) | LangChain 里(代码) |
|---|---|---|
| 登录 | 在网页上登录账号 | 赋值 API key |
| 选择大模型 | 在聊天框菜单选择 GPT-4、GPT-3.5 等 | 实例化语言模型类,设置模型参数 |
| 系统提示词(system prompt) | 在设置里 | 实例化 prompt 模版类,设置 style 字符串 |
| 输入问题 | 在聊天框输入问题 | 实例化 prompt 模版类,设置 text 字符串 |
| 获取回答 | 在聊天框显示回答 | 将 prompt 实例传入语言模型实例的方法,获取返回值 |
| 聊天记忆 | 在同一个对话中继续聊天 | 实例化一个 memory 类,再实例化一个 chain 类把语言模型和 memory 包进来,将 prompt 实例传入 chain 实例的方法 注:memory 支持一次性手动传入多组聊天(AI 的回答也可以手动指定) |
| 历史记录 | 查看一个对话 | 调用 memory 的查看方法 |
有一些事情需要注意:
大模型本身是没有记忆的,每次输入 prompt 提问,对大模型而言都是独立的。ChatGPT 和 LangChain 实现聊天记忆的做法都是在大模型外挂载了一块记忆,在继续上下文的聊天时,把记忆中的对话内容连同当前的 prompt 全部输入给大模型的。
LangChain 相比 ChatGPT,由于是代码控制,多了很多高级的、可定制的功能,例如:
限制聊天记忆(为了节省资源):聊天记忆选择取前 k 个对话(window memory),聊天记忆限制最大 token 数量,聊天记忆只存储 AI 自己总结的 summary 文本;
可以给输出加解析器,进一步精确输出。解析器
langchain.output_parsers被包裹在了 prompt 模版里面。
3 LangChain 核心功能:链
LangChain 的核心功能,正如名字所示,是链(chain),这个是其实现多步推理的关键。
链的最小单元是链条,可以理解为一个只回答固定问题的小的 AI 聊天助手,它接受输入并输出大模型给出的围绕固定问题的回答。在 LangChain 中,这个最小单元是 LLMChain 类,在实例化时指定使用的模型(llm 参数)和固定问题(prompt 参数),可以调用 run 方法给它输入并返回输出。
在代码中,这些链条的输入输出可以互相连接,从而得到链:
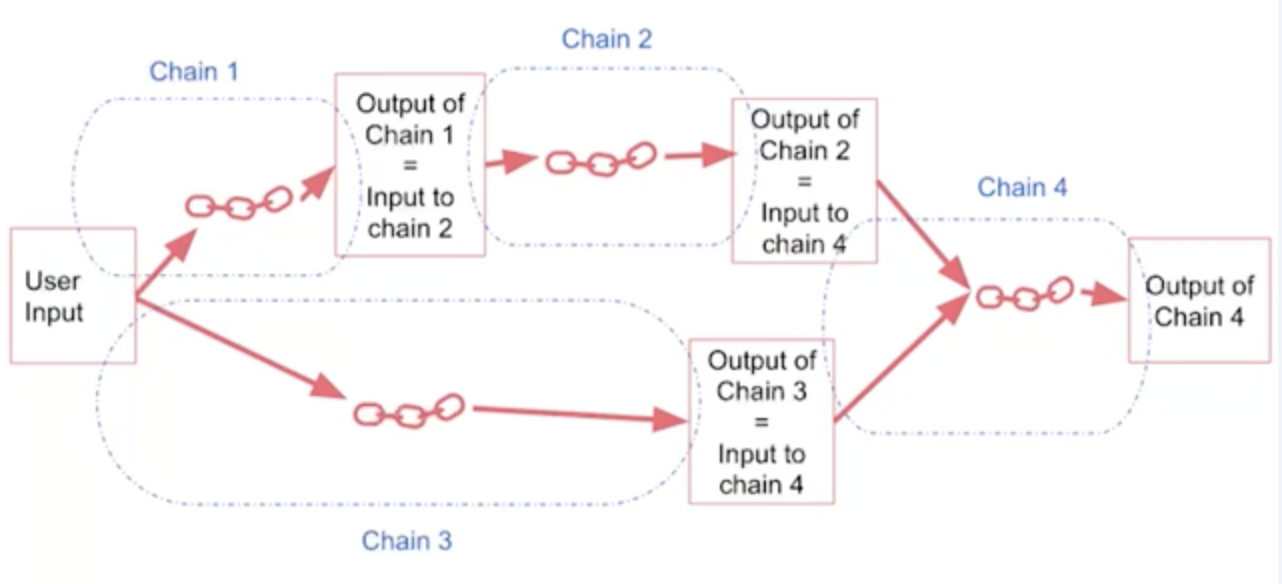
这样的话,用户的一个复杂的输入可以在一个定义好的思维顺序中逐步推理得到答案。大脑(大模型)的负担由此减轻,它不需要处理一整个复杂的输入一步得到答案,而只需在每个链条上回答好其问题,LangChain 会在外面自动将其组织成最终的答案。这种模式尤其适合需要多步有固定流程的文本,如计算机指令。
链条之间的链接关系本质上是一种有向无环图。根据不同的图结构,LangChain 预定义了不同的链类型,如:
- 顺序链(
SequentialChain):把多个LLMChain顺序连接; - 多 prompt 链(
MultipromptChain):通过路由链(RouterChain),根据输出判断进入哪个子链(LLMChain)。这个相当于链的 if-else 语句;
4 处理文件
大模型可以处理文件(大串带格式的文本)乃至多个文件,在 ChatGPT 中可以上传文件进行提问、检索,LangChain 也可以在代码层面实现这个功能。
你可能会问,直接把多个文件的文本一起输入到大模型里不就行了?但现实是:大模型一个输入只能处理几千个词,例如如果你给 ChatGPT 的输入特别长,它会拒绝并提示你。所以,大模型必须把文件拆开处理。
首先,在现在的大模型中,最常见的做法是存储文本的 embedding:将文件打散成小块,每块包含一小段文本,计算它的 embedding(维度相同,注意,计算 embedding 的方法每家都不一样),再将各小块的 embedding 纵向拼接在一起成为矩阵存起来。
然后,大模型会采取不同的策略,处理各个小块。例如:
- 独立处理每个小块,得到各自的答案然后再总结到一起,这样缺点很明显,缺少了小块之间的关系信息;
- 顺序处理每个小块,得到的答案增量式修改;
- 独立处理每个小块的时候得到一个分数,答案只汇总分数高的;
- 最普通的办法是堆叠,即把小块堆到一起输入给大模型,这样就是上面的那种不推荐的做法。
在 LangChain 中,所有的这些功能都可以通过代码实现。LangChain 有完全封装好的接口(langchain.indexes)支持一步处理文档,也可以定制里面的细节(链类型 RetrievalQA)。LangChain 设计了专门的模块 langchain.embeddings、langchain.vectorstores 来计算和存储 embedding。
5 工具与 Agent
除了 AI 聊天助手,现在的 AI 已经拥有了借助各种外部工具帮助输出的能力,例如调用搜索引擎的搜索结果、唤出计算器帮助计算数学问题、从数据库中抽取相关条目等。在 ChatGPT 中可以看到,当我们询问一个知识性的问题时,ChatGPT 往往会提示正在搜索互联网上的内容,然后根据搜索结果判断下一步该怎么思考,最终获得答案。这种具有规划能力的,能根据当前思考状态判断下一步该做什么,调用什么工具并自动执行,给出最后的结果的 AI,就是现在特别火的 agent,它是 AI 走向通用人工智能的第一步。
请注意,这里的 agent 与传统 AI 研究所指的 agent 概念不一样。在传统的 AI 研究中,一个 agent 就是能感知环境并根据目标或策略采取行动的系统,概念更宽泛。
开发 agent 是 LangChain 的终极目标。上面已经定义了各种链,不过它们最多等同于 AI 聊天助手,要像在代码中实现 agent,还需要融合各种外部工具的接口。这些工具已经接入了 LangChain,可以通过 langchain.agents.load_tools() 直接拿来用。
要使用大模型来开发 agent,请将大模型的 temperature 设为 0,这样使大模型的输出风格更精确,更适合开发 agent。
首先列举一下 LangChain 允许使用的工具和它们的用途:
llm-math:计算器;wikipedia:维基百科搜索;PythonREPLTool():Python 代码执行器,可以执行任意 Python 代码;- …
工具本质上就是一个函数,接受输入并返回输出。LangChain 就是 Python 代码,所以自己写的 Python 函数也可以接入 LangChain。Agent 的任务是决定什么时候调用哪个工具,所以这个自己写的 Python 函数最好要把注释写清楚,方便大模型理解工具的用途和调用的时机。
目前的大模型已经有了这个能力,例如 OpenAI 发布的 Function Calling,微调了大模型让它可以看懂函数信息文本,从而可以输出需不需要调用该函数、如果需要的话传什么参数这些信息。这些信息直接就是JSON格式,不需要 LangChain 等工具作处理或解析,是可以直接传入函数去执行的。LangChain 的作用,就是在下游更好地处理这些信息,让执行真正有序实现。
自定义的 Python 函数甚至也可以用大模型!这个就比较像链条了。例如,可以写一个工具函数 tagging 或 extraction,在里面包裹一个大模型,prompt 为“请分析文本,给这段文本打标签” 或 “请分析文本,提取其中的…“,函数输出就是大模型的输出。这一套模式可以用 PyDantic 的语法进一步简化,这里不讲细节。
在 LangChain 中,工具是就是函数,但在实现上外面包了一层装饰器 @tool。工具和函数之间可以互相转换。
在 LangChain 中,工具是与模型绑定的,而每个链条都是与某个模型绑定,所以链条上也就对应着一组工具。怎么确定链条上用不用工具,如果用,用哪些工具呢?这个不需要写 LangChain 代码人为指定,而是由大模型自己根据输入决定的,因为我们已经说过,大模型已经具备了 Function Calling 的能力,就是指的这些事情。LangChain 能控制的是,在大模型做出不同的决定后,继续走哪条链条。这个就是工具路由(tool routing),它不是通过路由链 RouterChain 实现的,而是通过一种专门解析链工具使用情况的解析器 AgentOutputParser 输出是调用哪个工具这一信息,然后接一个硬编码的路由函数(即 if-else 语句)来决定走哪条链条的。
一个复杂、健壮的 agent 通常会在使用工具上进行很多策略设计,来确保工具调用的正确性和安全性,例如循环重复调用工具,直到得到满意的结果;调用次数限制;错误处理与重试。这些逻辑需要人为写在代码里,LangChain 也提供了很多方便的工具实现这些逻辑。更高级的逻辑,都已经有论文发表了,例如 ReAct。实现它们,用 LangGraph 更方便,它是 LangChain 的一个子项目,专门用来设计复杂的 agent 流程图的。我为 LangGraph 单独开了一篇笔记。
这样,LangChain 最终就实现了一个完整的 agent 系统,能根据输入自动规划思维路径,调用工具并执行,最终输出结果。这就很相当于现在这个能融合多步推理、自动规划调用工具的 ChatGPT 了(现在的 ChatGPT 可以看到它的思考过程,就是一个 agent)。
6 一个完整的 LangChain 应用
一个完整的 LangChain 应用写法通常是用一个大的 class 来封装所有的链条、工具、模型,然后提供一个统一的接口,再把这些接口接到展示界面上,这个界面可以是命令行交互,也可以是网页 App,甚至是手机 App。
这样一个应用完全可以实现 ChatGPT 的全部功能了,甚至可以更强大,因为代码的可定制性更强。
这时候有人可能会问,如果 LangChain 能写出 ChatGPT,而且 LangChain 是开源免费的,但 ChatGPT 收费,那为什么还要用 ChatGPT?
别忘了!LangChain 调用的就是 OpenAI 的 API,OpenAI 的 API 是收费的!LangChain 只是一个中间层,帮你更好地组织和调用 OpenAI 的 API 而已。
7 评估与调试 LangChain 代码
用 LangChain 开发的大模型应用有两个部分:大模型(大脑)和 LangChain 系统(框架)。也就是说,当应用出问题时,有可能是 LangChain 代码出了问题,也可能是大模型本身不准确。LangChain 系统是精确的、人为设计的,所以有明确的正确、错误,检查它属于调试代码。对于大模型本身,由于它的不确定性和自然语言的不精确性,只能是评估模型。本节讨论当应用出问题时,怎么去检查这两个部分。
LangChain 支持用一行代码对模型多次输入,独立地得到多个结果。这就其实就是深度学习测试时的数据集循环。LangChain 甚至还设计了图形化界面 LangSmith 来可视化评估结果,类似 TensorBoard。
在大模型时代,评估模型本身甚至都可以利用大模型。例如,可以用大模型生成测试用例。LangChain 为这些评估需求提供了一些特制的链条。例如,QAGenerateChain 可以输入文档,输出关于该文档的一系列问答题目,可以用来评估模型。在拿到测试结果时,也可以用 QAEvalChain 让大模型来做评估这件事,包括判断对错、打分。
你可能会问,用大模型来评估自己,这不是个悖论吗?确实是这样的,但这里更重要的问题是,我们很难写出确定的规则精确地评估大模型,因为这些问答问题都是开放的,也许有的问题我们肉眼来看大模型确实答的意思对了,但是可能不满足严格的规则而被判定为错误。对于不较真的问题,就得用不较真的办法评估,这和考试判卷是一样的。这种不那么较真的评估,要么是让人自己来,要么就只能交给大模型了。
要调试 LangChain 代码,LangChain 也提供了方便的工具。首先,一个特别方便的工具,打开 langchain.debug=True 后,可以看到在输入在链中的处理顺序、中间结果甚至系统信息,而不只是输出结果。
脚注
LangChain 也有 JavaScript、TypeScript 的版本,称为 LangChain.js。↩︎