Hash algorithm is a method that turns an one-dimension array into a quicker data structure called hash table, and correspondingly, turns the operations (search, insert, modify, delete) on the array into operations on the hash table.
As we know, the operations on the array cost
The hash algorithm comprises two parts:
- Construct the hash table beforehand;
- Operation on the hash table when requested.
which makes the hash algorithm more of a data structure rather than an algorithm. That’s why it is often called hash table interchangeably.
The array can contain any type of data (other than nested arrays), including integer, string, float, etc. Any type of array can be turned into a hash table.
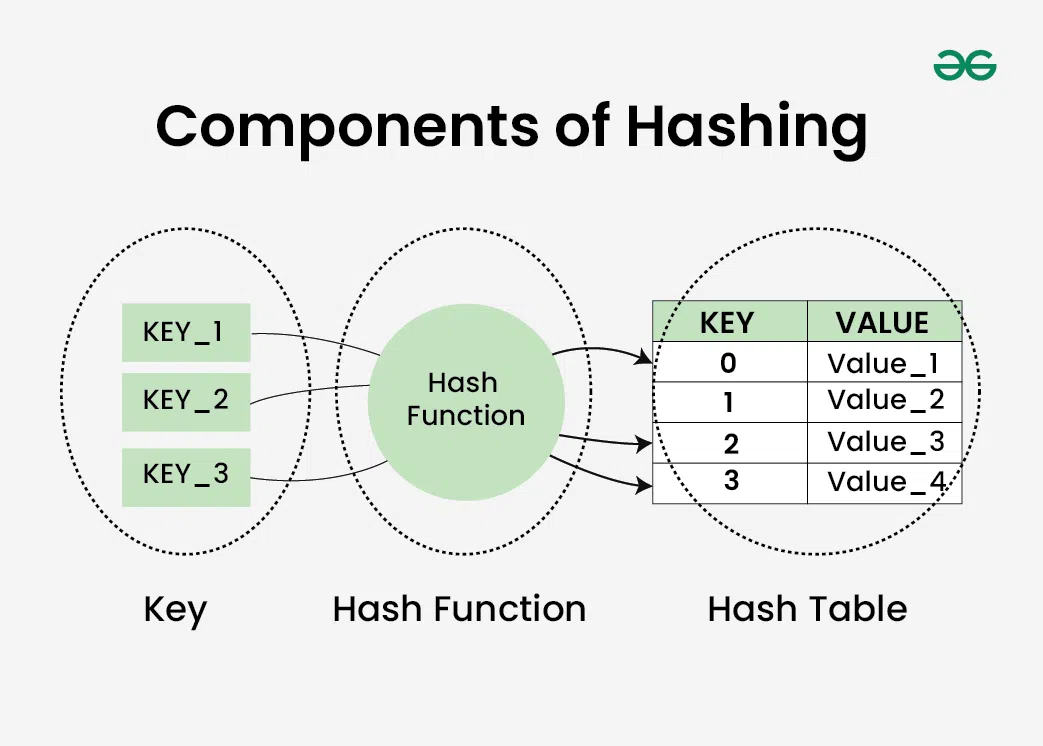
Hash table is still a one-dimension array. However, it works together with the hash function, or else it is just an normal array.
Hash function is a function or map
This hash value is used as the index of the data in the hash table, which we will cover later. The index of an array is always a non-negative integer, so the hash value must be a non-negative integer.
Hash algorithm takes an array and applies a hash function to each element, generating a hash value for each element. These hash values are then used as indices to store the elements in the hash table, mapping the original array elements to their corresponding positions in the hash table.
In English, “hash” means “to chop up into small pieces”, or a kind of dish that is hashed from leftover food, with the extended meaning “to confuse or mix up”. The word “hash” was chosen because a hash function “messes up” or “scrambles” data — just like chopping and mixing ingredients in a hash meal.
Hash function is pre-defined. Hash function is not a specific function but any function that can work in the hash algorithm. Hash algorithm is all about choosing a hash function. When the hash function is set, the hash algorithm is set. Hash table is the result of the hash algorithm turning an array into.
We take search operation as an example. In conventional array, as we know nothing about where the query data is stored, we have to brutally loop through the array to find the data, which is
Ideally, it must be an injective function, which means different data must have different hash values (if
However, in practice, hash function cannot achieve this property and collisions do happen. In this case, the hash algorithm must handle collisions.
In this case, the hash algorithm must handle collisions, which is part of the algorithm. It includes:
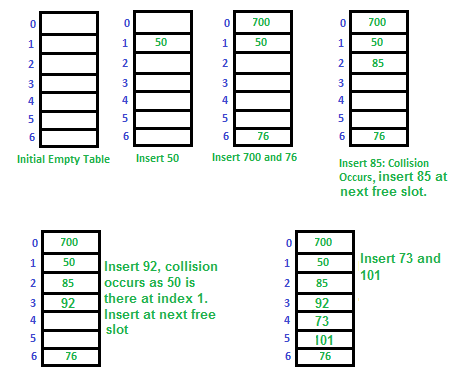
- When constructing the hash table: if a new element to be put into the hash table finds an existing element occupying its hash value position, the algorithm needs to provide a way to find a new position to store the new element.
- When searching for an element (operating): as the hash table construction suggests, the element may not be in the position of its hash value, so the algorithm needs to provide a way to find the element in the hash table starting from its hash value position.
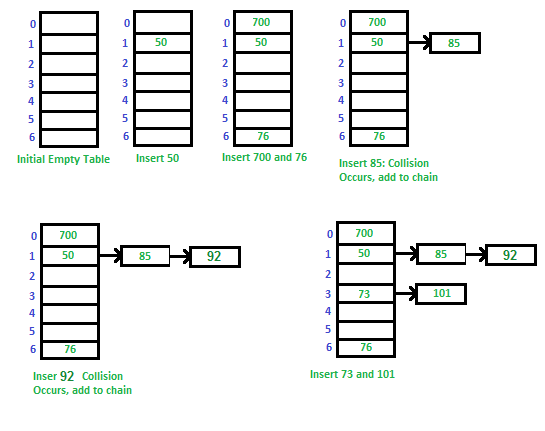
- Chaining: Each position in the hash table points to a linked list (or another data structure) that holds all elements that hash to the same index. When a collision occurs, the new element is simply added to the list at that index. In this case the hash table is not a one-dimension array anymore, but an array of linked lists.
- Open Addressing: When a collision occurs, the algorithm searches for the next available position in the hash table to store the new element. The next position to probe for availability can be defined in various ways, such as:
- Linear probing: checking the next index sequentially, for example, if the hash value is
- Quadratic probing: checking indices in a quadratic manner, for example, if the hash value is
- Double hashing: it is still a linear probing, but the step size is not a fixed
Note that if the probing reach the end of the hash table, it will wrap around to the beginning of the table, so that the probing can continue until an empty position is found. Mathematically, it is
Hash table reduces the operation complexity, but it could introduce some overhead, mainly the memory usage for storing the hash table. Because each value must be stored in the hash table, the length of the hash table is at least equal to the original array. It also depends on the quality of the hash function. Some bad hash functions can map to very large indices, leaving a lot of empty space in the hash table.
If the array is very small, the overhead of applying the hash function may not be worth it, and a simple array might be more efficient.
In practice, we often use existing hash functions provided by programming languages or libraries, as they are well-tested and optimized. However, in some cases, especially when dealing with specific data types or structures, we may need to design a custom hash function to achieve better performance or to meet specific requirements.
- Python dictionary is implemented as hash table to store key-value pairs. That is why Python dictionary can retrieve the value of a key immediately in
HashMap, C++’sunordered_map, and JavaScript’sObjectorMap. - Caching: Hash tables are used in caching mechanisms to store and quickly retrieve frequently accessed data. The caching mechanism is widely used in web applications, databases, and operating systems to improve performance by reducing the need to recompute or fetch data repeatedly.
- Database Indexing: Hash indexes allow for fast data retrieval in databases.
- Cryptography: For some hash functions, it is very difficult to reverse the hash function. That’s why hash functions are used in passcodes. For example, the password of a user is stored in the database as a hash value, so that even if the database is compromised, the original password cannot be easily retrieved. This is called password hashing.
- Data Deduplication and Integrity Check: Some hash functions can map any length of binary sequence. Because every file or data is a binary sequence in computer, they all have a unique hash value, which is exactly corresponding to their unique content. Therefore, if two files or data have the same hash value, they are exactly the same. This feature makes hash algorithm useful for checking file or data integrity.