My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
The decision tree is a supervised machine learning algorithm that can be used for both classification and regression tasks. It also refers to the tree-based model built by the algorithm.
Decision tree is simply a supervised learning model that maps input features to output labels.
Inputs:
- A set of input features (independent variables)
Outputs:
- A target variable (dependent variable)
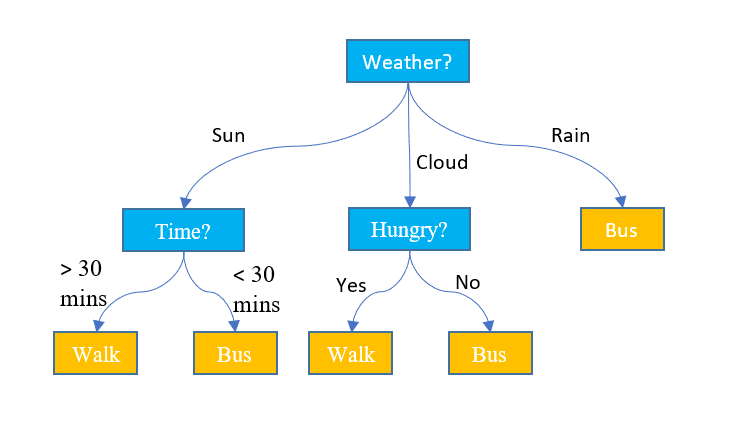
A decision tree model is structured as a if-else tree, where each internal node represents a decision based on the value of a specific feature, each branch represents the outcome of that decision, and each leaf node represents a final prediction or output.
The tree structure itself is the model parameter. In each node, the threshold value of the feature used for splitting is also a model parameter. They are learned from the training data during the training process.
There are several algorithms to train a decision tree, including:
- ID3 (Iterative Dichotomiser 3)
- C4.5
- CART (Classification and Regression Trees)