My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Attention is a type of neural network layer that allows neural networks to focus on specific parts of the input sequence when making predictions.
Attention was first introduced in 2014 (Bahdanau, Cho, and Bengio 2014) for machine translation tasks.
The background was the need to improve the performance of sequence-to-sequence models, particularly for tasks like machine translation. Traditional RNNs struggled with long-range dependencies and often produced poor translations for long sentences. The attention mechanism allowed the model to focus on specific parts of the input sequence when generating each word in the output sequence, significantly improving translation quality.
Later, the self-attention mechanism was proposed in the Transformer architecture (Vaswani et al. 2017) in 2017, which further advanced the use of attention in deep learning. Please refer to AI Concept Takeaway: Transformer for more details.
We first discuss the attention mechanism in general, then the attention layer in neural networks.
Given a set of vectors, we want to know an other vector should pay attention to which vectors, and how much attention should be paid to each vector. This is what the attention mechanism does.
Input:
- Query: a vector
- Targets: a dictionary of vectors
- Key
- Value
- Key
Output:
- Attention Scores: a vector of attention scores
- Weighted Sum Value: a vector
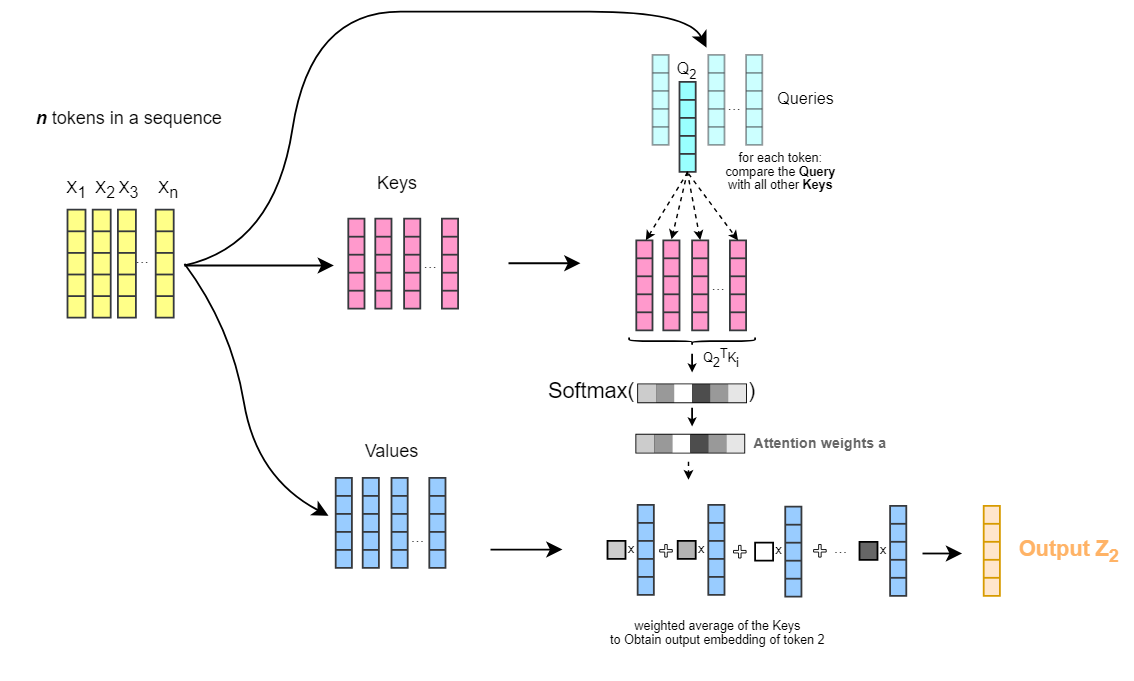
There can be multiple query vectors
The attention scores are computed by the similarity between the query
The attention scores are each 0-1 value, and the sum of all scores is 1. This can be achieved by applying the softmax function to the similarity scores. But before applying the softmax function, the similarity scores are often scaled by the square root of the dimension of the key vectors
This is known as scaled dot-product attention.
The matrix form of the attention computation is:
It is often seen as a single attention function:
The attention scores are computed by the similarity between the query
The attention scores are each 0-1 value, and the sum of all scores is 1. This can be achieved by applying the softmax function to the similarity scores. But before applying the softmax function, the similarity scores are often scaled by the square root of the dimension of the key vectors
This is known as scaled dot-product attention.
The matrix form of the attention computation is:
It is often seen as a single attention function:
In neural networks, the attention mechanism is typically implemented as an attention layer. The input to the attention layer is a set of query, key, and value vectors, which are usually obtained by applying linear transformations to the input data
Attention layer is a parameterised layer. The weights of the linear transformations are learned during training, allowing the model to adaptively learn how to compute attention based on the input data. These are the parameters of the attention layer.
The earliest use of attention in neural networks was in sequence-to-sequence models for machine translation (Bahdanau, Cho, and Bengio 2014). In these years, RNN-based encoder-decoder architectures were widely used for sequence-to-sequence tasks. Here the query vector is (a linear transformation of) the decoder hidden state at the current time step, and the key and value vectors are (linear transformations of) the encoder hidden states at all time steps. The attention output represents a context vector that summarizes the relevant information from the input sequence based on the current decoder state’s attention. The prediction is then made based on this, which is connected to the output layer.
Later, the self-attention mechanism was proposed in the Transformer architecture (Vaswani et al. 2017), which further advanced the use of attention in deep learning. In self-attention, the query, key, and value vectors are all derived from the same input sequence