My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
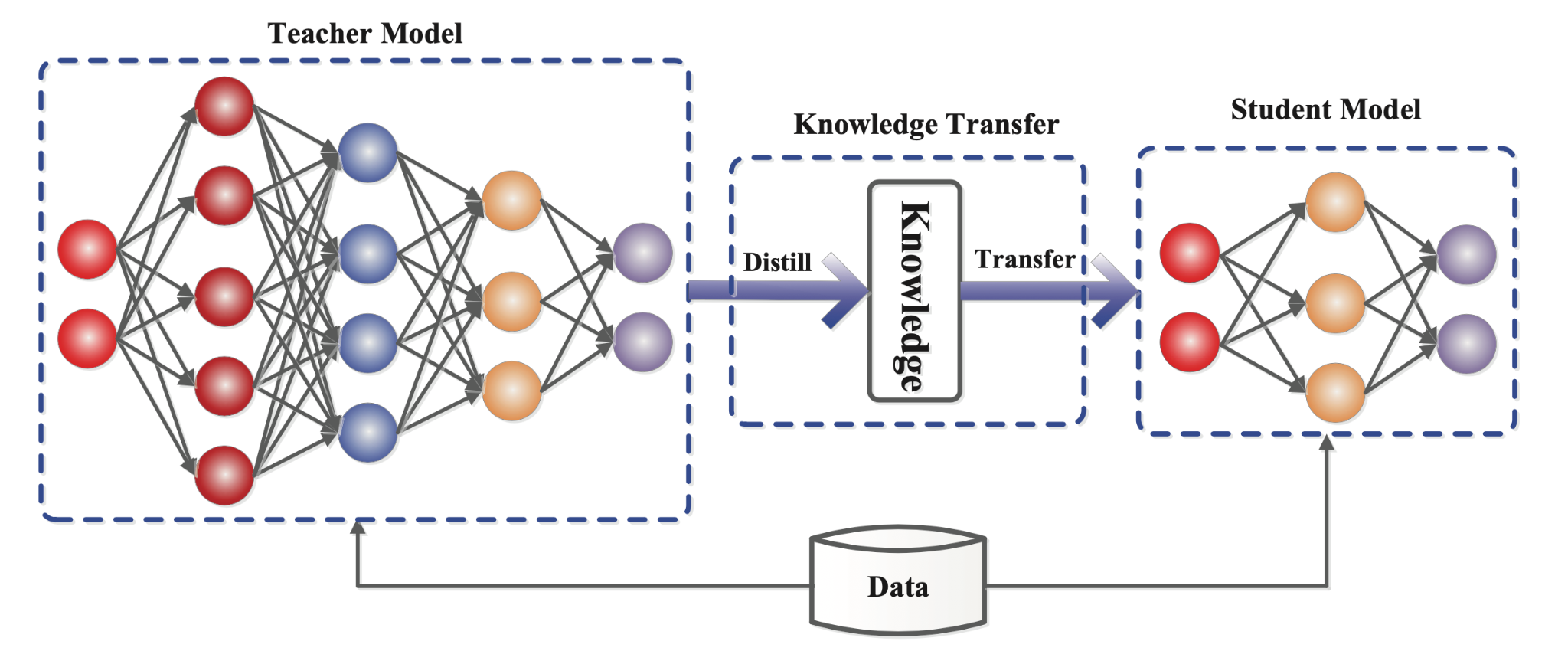
Knowledge distillation is a technique to transfer knowledge from a large model (teacher) to a smaller model (student). Intuitively, it distills the knowledge from a large model like in a chemistry lab. It’s a model compression technique.
Geoffrey Hinton and his collaborators first introduced knowledge distillation in 2015 in a NIPS workshop paper (Hinton, Vinyals, and Dean 2015). At that age of deep learning, models (particularly deep neural networks like CNNs and RNNs) were becoming increasingly powerful, but they also had a huge computational cost. Knowledge distillation was proposed as a way to compress the knowledge and reduce the cost.
Knowledge distillation made a big splash in the AI community. It suits particularly well in resource-constrained environments, like mobile devices, edge devices, and IoT devices, and accelerated several area such as edge computing. For example, edge computing thrived around mid-2010s, whose techniques were certainly benefited from knowledge distillation.
DeepSeek, a recent popular Chinese large language model, is suspected to be distilled from ChatGPT, with the help of knowledge distillation.
The temperature in knowledge distillation is a tuning knob (that we call hyperparameter) that controls how much knowledge is distilled from the teacher model. Like what it means in literal, the hotter the temperature, the softer the probability distribution, thus similar to that the physical temperature controls the intensity of the distillation process.
Such idea of transferring knowledge from a model to another model can be used in continual learning model between different tasks. For example, the knowledge of previous tasks can be distilled to a new model for the new task, which provide a way to prevent forgetting previous tasks.
Some classic work in continual learning adopts this idea, such as iCaRL (Rebuffi et al. 2017) and LwF (Li and Hoiem 2017).
Inputs:
- A smaller network \(g(\theta)\), not trained. It is the target model, i.e. the student model
- Training dataset \(\mathcal{D}\) for the target model
- A larger network \(f\) well trained elsewhere. It is the reference model that the target model refers to, i.e. the teacher model
Outputs:
- Trained smaller network \(g(\theta^\star)\), with its knowledge distilled from \(f\), instead of trained from scratch using \(\mathcal{D}\)
Knowledge distillation tries to minimise the distillation loss:
\[L_{\text{distillation}}(\theta) = \sum_{\mathbf{x}\in\mathcal{D}} \text{distance}\left(f(\mathbf{x}), g(\mathbf{x}; \theta)\right)\]
When training the student model, it encourages the student model’s outputs closer to teacher model’s outputs, over the data distribution (which is represented by the dataset). In other words, to let student mimic teacher in terms of the (output) feature. This is the key idea of knowledge distillation.
In theory, the outputs can be all of them. However, not all of them work in practice.
In the formula above, the outputs \(g(\mathbf{x}, \theta)\), \(f(\mathbf{x})\) are the probabilities of the classes, which are the outputs after the softmax function. The softmax function is used to convert the logits to probabilities:
\[\text{softmax}(\mathbf{z})_k = \frac{\exp(z_k / T) }{\sum_{j=1}^C \exp(z_j / T) }, k = 1, \cdots, C\]
where \(C\) is the number of classes, \(z_k\) is the logit of class \(k\), \(T > 0\) is the temperature hyperparameter. It converts logits \((\mathbf{z}_1, \cdots, \mathbf{z}_C)\) to probabilities \((\text{softmax}(\mathbf{z})_1, \cdots, \text{softmax}(\mathbf{z})_C)\).
Usually it’s the KL divergence, but there are exceptions (for example, LwF in continual learning uses cross entropy). This metric is used to measure the difference between two probability distributions. However, I wouldn’t give a full explanation from the statistics perspective, I’d just put the formula here to let you know how it calculates the difference between two probability value tensors:
\[\text{KL}(\mathbf{p}, \mathbf{q}) = \sum_{k=1}^C p_k \log\left(\frac{p_k}{q_k}\right)\]
where \(\mathbf{p} = (p_1, \cdots, p_C)\), \(\mathbf{q} = (q_1, \cdots, q_C)\) are the two probability tensors.
Be aware that the KL divergence is not symmetric, so the order matters. In the distillation loss, it’s \(\text{KL}(f(\mathbf{x}), g(\mathbf{x}; \theta))\).
In real implementation, the general practice is minimising a balance between the distillation loss and the original loss (e.g., cross-entropy loss for classification, i.e. the distance from the ground truth label \(y\)). The final loss function is:
\[\min_{\theta} L(\theta) = \lambda L_{\text{distillation}}(\theta) + (1-\lambda) L_{\text{classification}}(\theta), 0<\lambda<1\] \[L_{\text{classification}}(\theta) = \sum_{(\mathbf{x}, y)\in\mathcal{D}} \text{loss}\left(g(\mathbf{x}; \theta), y\right)\]
where \(\lambda\) is a hyperparameter to balance the two losses.
“Temperature = 1” means using the original outputs of the teacher model, which is very sharp. This makes it difficult for the student model to learn anything about the relative relationships between other classes. Essentially, the student might just focus on mimicking the teacher’s class prediction without understanding why certain classes are more likely than others.
In continual learning, knowledge distillation is generally used to distill the knowledge of previous tasks to the new model when training the new task, which provide a way to prevent forgetting previous tasks. It is formed as a regularisation term \(R(\theta)\) in the loss function of new task training:
\[ \min_\theta \mathcal{L}^{(t)}(\theta) = \mathcal{L}^{(t)}_{\text{cls}}(\theta) + \lambda R(\theta) \]
LwF (Li and Hoiem 2017) distills the outputs of previous tasks to the new model when training the new task. The distillation loss is the same as the original knowledge distillation, but the teacher model is the model trained on previous tasks. The data of distillation is from the new task. The previous models are stored in a memory buffer and used as the teacher model.
iCaRL (Rebuffi et al. 2017) applies only to CIL setting. It distills the knowledge of exemplars (replay data selected manually and stored in a memory buffer) of previous tasks to the new model when training the new task. The data of distillation is the examplars from the previous tasks. The last previous model help calculate the output probabilities of the exemplars at the beginning of training new task, then deleted.