My takeaway series follow a Q&A format to explain AI concepts at three levels:
TipConceptual Level
Anyone with general knowledge can understand them.
WarningImplementation Level
For anyone who wants to dive into the code implementation details of the concept.
ImportantMathematical Level
For anyone who wants to understand the mathematics behind the technique.
The Concept of Data Normalisation
TipWhat is data normalisation?
Data normalisation is a technique to change the values of numeric columns in the dataset to a common scale and position, without distorting differences in the ranges of values or losing information.
TipWhat does data normalisation do?
Data normalisation has two main parts:
Zero-centring: To shift the distribution of each feature to distribute around zero.
Scaling: To scale the distribution of each feature to distribute within a specific range, such as -1 to 1 or 0 to 1.
ImportantWhy do we need zero-centring data?
Zero-centring data is basically for making the learning more efficient and stable.
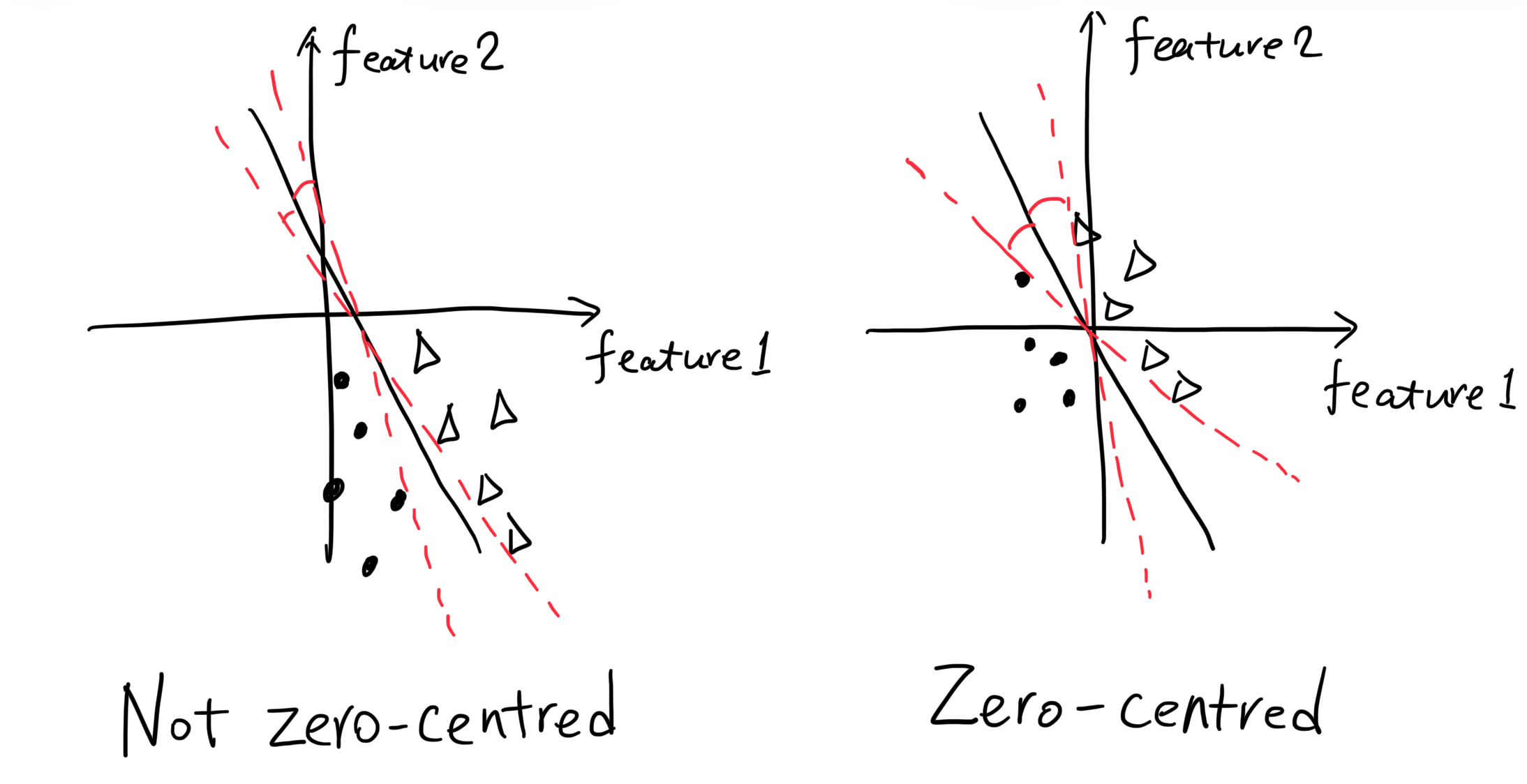
First, data that are not zero-centred are more sensitive to the parameter change. We take a simple logistic regression model as an example. In the following figure, the left plot shows non-zero-centred features, while the right plot shows zero-centred features. The decision boundary (the line), which is decided by the parameters (weights and bias), has less room to rotate in the left plot than in the right plot. Therefore, the model with non-zero-centred features is more sensitive to the weight change. That is, a small update of the weights will cause a large change in the decision boundary, making the model less stable to learn.
Second, non-zero-centred data make the bias parameter dominate, since the weights don’t have much room to change, and the non-zero-centred data themselves has a certain bias to learn. This also makes the learning less efficient.
ImportantWhy do we need scaling data?
Scaling is also for making the learning more efficient and stable.
First, features with different scales also make certain weights dominate. We take a simple logistic regression model as an example:
\[
f(x) = \sigma(w_1 x_1 + w_2 x_2 + b)
\]
In this model, if the scale of feature \(x_1\) is much larger than that of feature \(x_2\), then a small change in weight \(w_1\) will cause a large change in the output, while a large change in weight \(w_2\) will only cause a small change in the output. Therefore, the learning of weight \(w_1\) will dominate the learning of weight \(w_2\), making the learning less efficient.
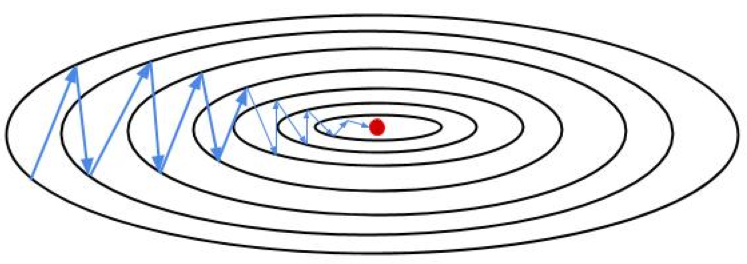
The loss function is also skewed by the feature with a larger scale. If we use the same learning rate for all weights, the weight corresponding to the feature with a larger scale will have a larger update, which sometimes can make the zig-zag phenomenon occur.
TipThe reason why we need data normalisation is revolving around making the learning more efficient and stable, which seems only training data needs to be normalised. What about validation and test data?
The validation and test data should be normalised using the exactly same way as the training data, because the model is trained on the normalised training data, and it expects the input data to be in the same distribution as the training data.
A good way to understand this is to think the normalisation as a part of the model. Now this model receives the original data and normalises it (using the same way) before feeding it to the network. This applies to all training, validation, and test data.
Ways of Data Normalisation
ImportantWhat are the common ways to normalise data?
For feature \(x\), the common ways to normalise it are:
Data Standardisation
\[ x' = \frac{x - \mu}{\sigma} \]
where \(\mu\) is the mean of the feature, and \(\sigma\) is the standard deviation of the feature. This can make the feature have a mean of \(0\) and a standard deviation of \(1\).
ImportantWhat are pros and cons of these two methods?
The data standardisation is not bounded, which means it does not have a fixed range. This can be a problem for some algorithms that expect the input data to be within a certain range.
The min-max normalisation is very sensitive to outliers, which means that if the feature has some extreme values, the normalised values will be very close to \(0\) or \(1\), and the other values will be squeezed in a small range.
TipWhen to use which method?
The data standardisation is more commonly used, especially for algorithms that assume the input data is normally distributed, such as linear regression, logistic regression, and neural networks.
The min-max normalisation is less common unless the algorithm specifically requires the input data to be within a certain range.