My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Residual Network (ResNet) is a specific convolutional neural network architecture. It is known for its residual connection design.
ResNet was proposed by Kaiming He et al in their 2015 paper (He et al. 2016). The background was to address the problem of training very deep neural networks. As neural networks become deeper, they tend to suffer from the vanishing gradient problem, making it difficult to train them effectively. ResNet introduced the concept of residual connections to mitigate this issue and enable the training of much deeper networks.
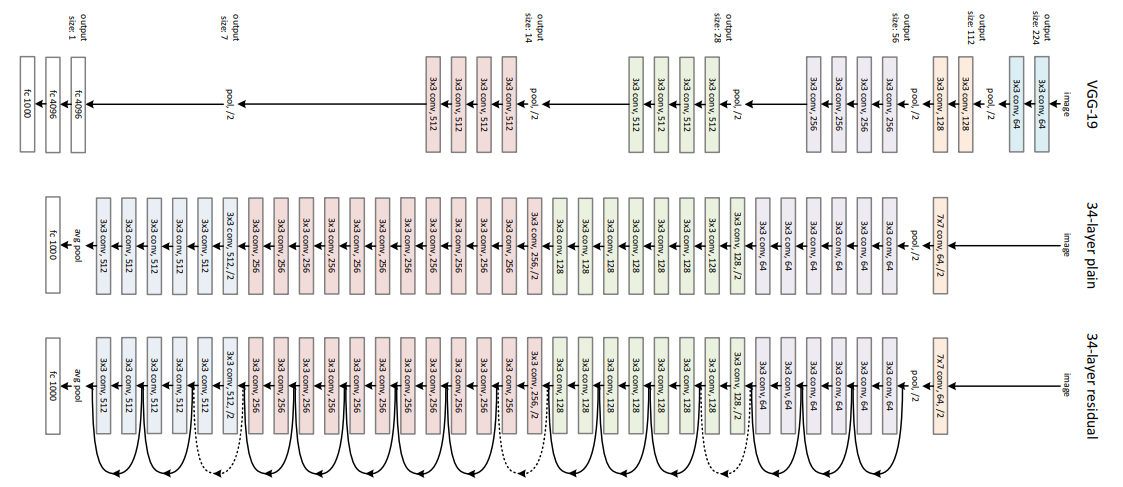
ResNet architecture consists of multiple residual blocks, each containing convolutional layers and residual connections. Note that there is only 2 pooling layers at the beginning and end of the network. There is no fully connected layer anywhere in the network.
ResNet has 5 versions: ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152. The number indicates the number of layers in the network. Figure 1 shows the architecture of ResNet-34 as an example.
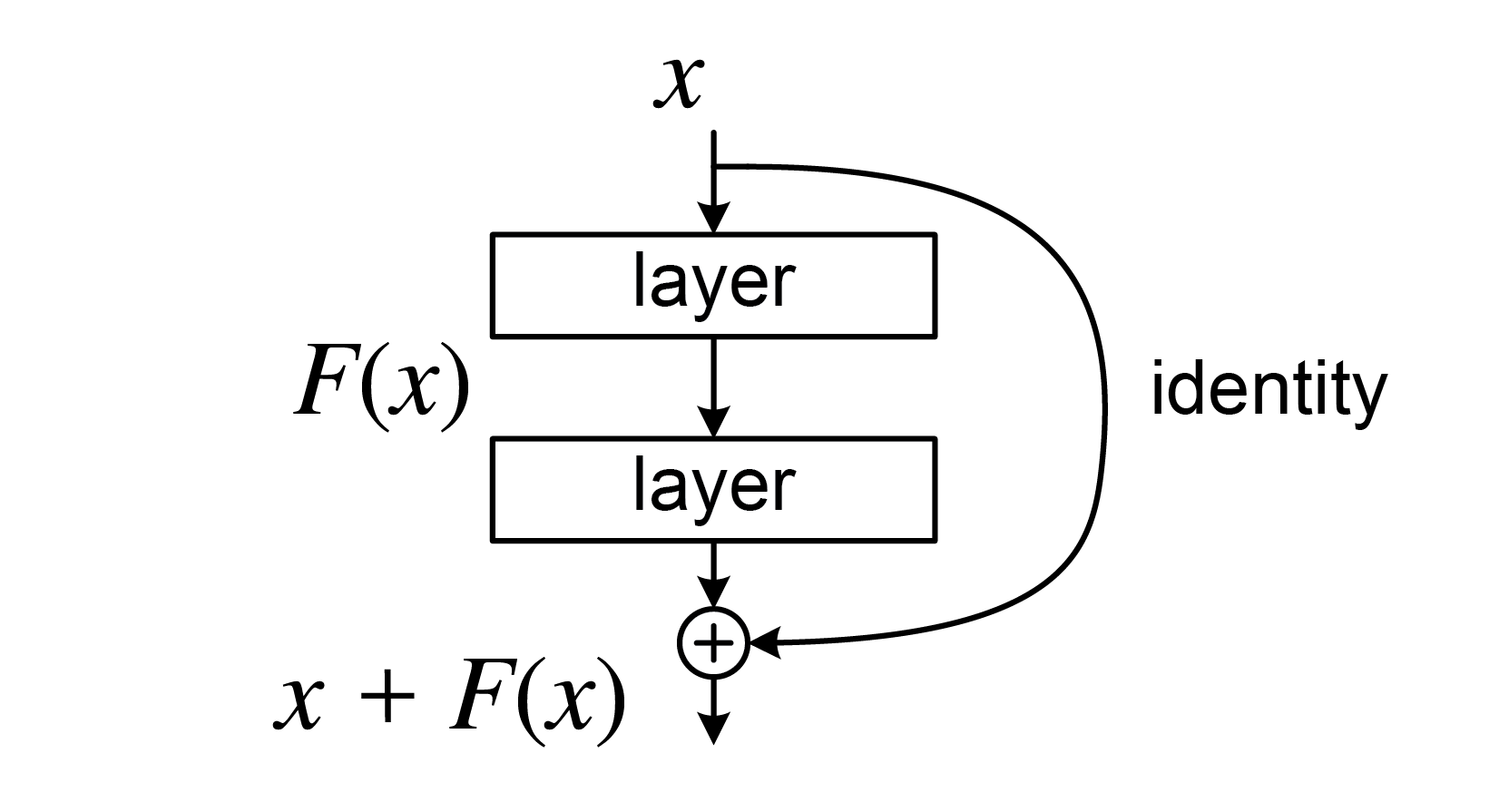
During the forward pass, the input to a residual block is added to the output of the block before passing it to the next layer. Taking a simple residual block with two convolutional layers as an example, if the input to the block is denoted as (x), and the output of the two convolutional layers is denoted as (F(x)), then the output of the residual block is given by:
\[ y = F(x) + x \]
This addition operation is known as a residual connection or skip connection.
The main purpose of residual connections is to address the vanishing gradient problem that occurs in deep neural networks. In the backpropagation, it is allowed to skip residual blocks through the shortcut path that residual connections provide. This helps to preserve the gradient during backpropagation, making it easier to train very deep networks.