My takeaway series follow a Q&A format to explain AI concepts at three levels:
Anyone with general knowledge can understand them.
For anyone who wants to dive into the code implementation details of the concept.
For anyone who wants to understand the mathematics behind the technique.
Batch normalisation belongs to a training technique that can accelerate and stabilise the training of deep neural networks. It appears as a layer in the neural network.
Batch normalisation was proposed by Sergey Ioffe and Christian Szegedy in 2015 in an ICML paper (Ioffe and Szegedy 2015). At that age of deep learning, deeper neural networks were rapidly developing and brought significant challenges in training. Batch normalisation was proposed to to help train models faster.
The term batch normalisation quite literally describes its function: it’s a layer that performs a normalisation operation on a batch of input data. normalisation is a mathematical transformation that rescales a collection of data points to a standard range without distorting the relative relationships between them.
Conceptually, normalisation requires multiple data points to compute the necessary statistics (like mean and variance). In deep learning, it’s often not feasible to load the entire training dataset into memory at once due to its size. Therefore, the data is typically divided into smaller mini-batches. Batch normalisation applies its normalisation procedure to each of these mini-batches individually as they are processed during training, hence the name ‘batch normalisation’.
The original batch normalisation paper (Ioffe and Szegedy 2015) explains its effectiveness through the concept of reducing internal covariate shift. Internal covariate shift refers to the change in the distribution of layer inputs during training, caused by updates in the parameters of preceding layers.
As illustrated in Figure 1, neural networks are modularised as layers. While the input
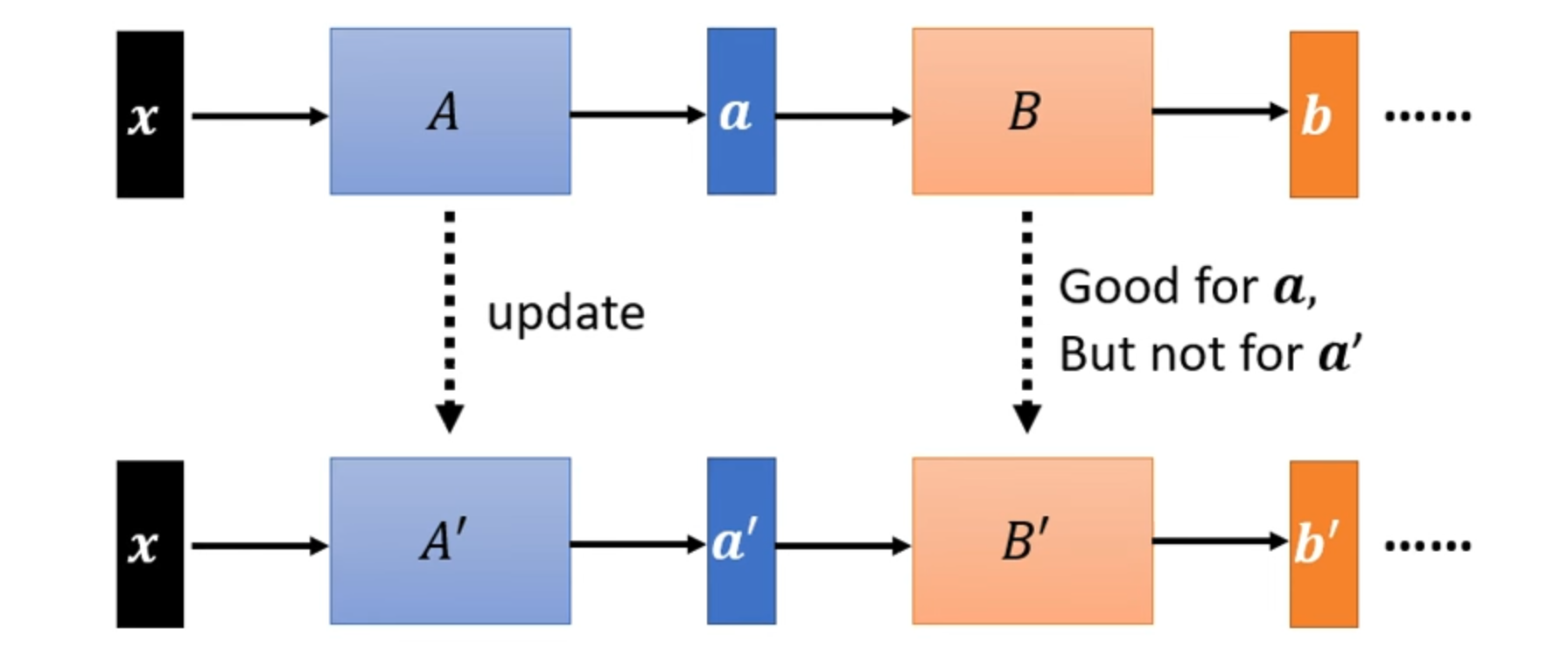
However, a later paper (Santurkar et al. 2018) questioned whether reducing internal covariate shift is truly the key reason BN is effective. They showed in both theory and experiment that the benefit of Batch normalisation is more accurately attributed to its ability to smooth and reshape the loss landscape, making gradients more predictable and training more stable. This effect leads to faster convergence and improved generalisation.
Batch normalisation works as a layer in a neural network, and like other layers, it has both inputs and outputs. Since it involves statistical normalisation, the input must be a batch of data.
Inputs:
- Input feature, either before activation
Outputs:
- Processed feature
Note that this can be imagined as a network batch size times larger.
Batch normalisation is actually a parameterised layer. It has learnable parameters that are optimised during training, similar to other layers in the network.
Although from the mechanism it seems like it only involves normalisation which is purely based on statistics (mean and variance) calculated from the input batch, batch normalisation introduces rescaling and shifting after the normalisation. This introduces two variables as learnable parameters:
- Rescaling parameter
They have the same dimension as number of neurons (features) in the layer, because the rescaling and shifting are applied to neuron-wise.
It involves two parts: normalisation and rescaling/shift.
- normalisation: Calculate the layer-wise mean and variance of the input feature
- Rescaling and shifting: scale and shift the normalised feature using the learnable parameters
As the formulation shows, batch normalisation relies on computing the mean and variance across a batch of data. If the batch size is too small, the estimated statistics can become noisy and unreliable, which may lead to unstable training and reduced model performance.
Therefore, it is generally recommended to use a moderately large batch size (e.g., 32 or more) to ensure stable and accurate normalisation.
First, rescaling and shifting are not exactly recovering the input before normalisation, because the mean and std are not necessarily the same.
Second, the purpose of introducing these parameters is to allow the model to learn the optimal range for each feature, instead of only
Third,
One simple way is skipping the batch normalisation layer, but this makes training and test different. As the batch is only to calculate the mean and std statistics for normalisation, the typical way is to use empirical statistics gathered during the training stage.
For example, PyTorch computes the moving average (accumulated mean and variance) during training:
and use these statistics to normalise the data during inference: